Finrandojin/alexandria-audiobookv5.0updated 17d ago
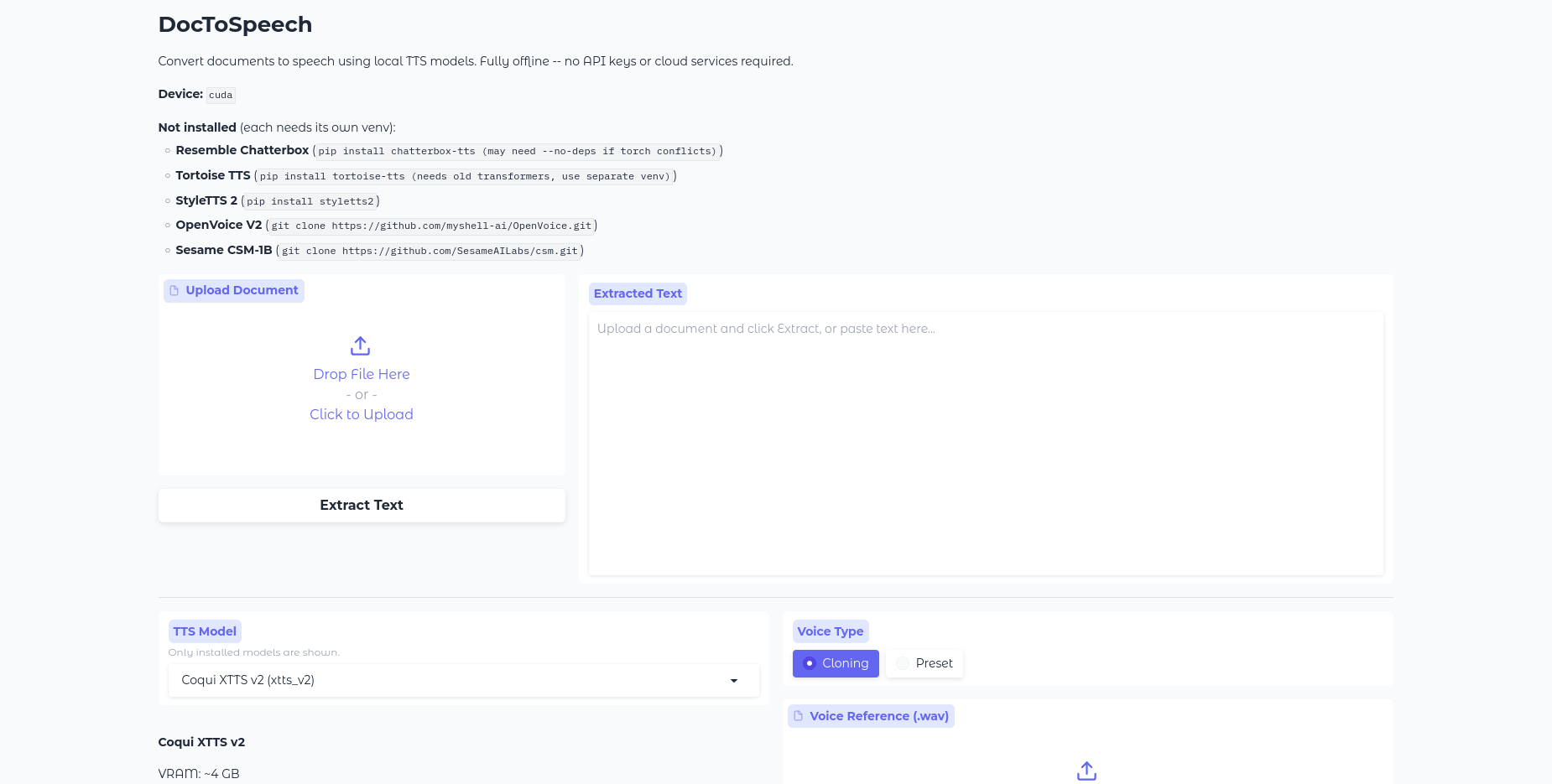
A multi-voice AI audiobook generator built on Qwen3-TTS — annotate scripts with an LLM, assign unique voices to each character, per-line style instructions for delivery, clone voices from reference audio, design new voices from text descriptions, train custom voices with LoRA fine-tuning, and export to MP3 or Audacity multi-track projects
Auris-BadBaDaki is Offline audiobook reader for EPUB, PDF, and TXT with local OmniVoice TTS, character-aware voices, per-book narrator control, and synced text highlighting.
Everything runs locally after setup. No API keys. No hosted TTS dependency.
pinokiofactory/clarity-refiners-uiv3.7updated 19d ago
An enhanced local port of finegrain-image-enhancer powered by Refiners (https://huggingface.co/spaces/finegrain/finegrain-image-enhancer), which was adapted from philz1337x's Clarity Upscaler (https://github.com/philz1337x/clarity-upscaler)
Bulk transcribe many YouTube videos, whole playlists, or your own uploaded audio/video files at once with faster-whisper. Outputs txt, srt, vtt, or json.
cocktailpeanut/stabledaw.pinokiov7.0updated 20d ago
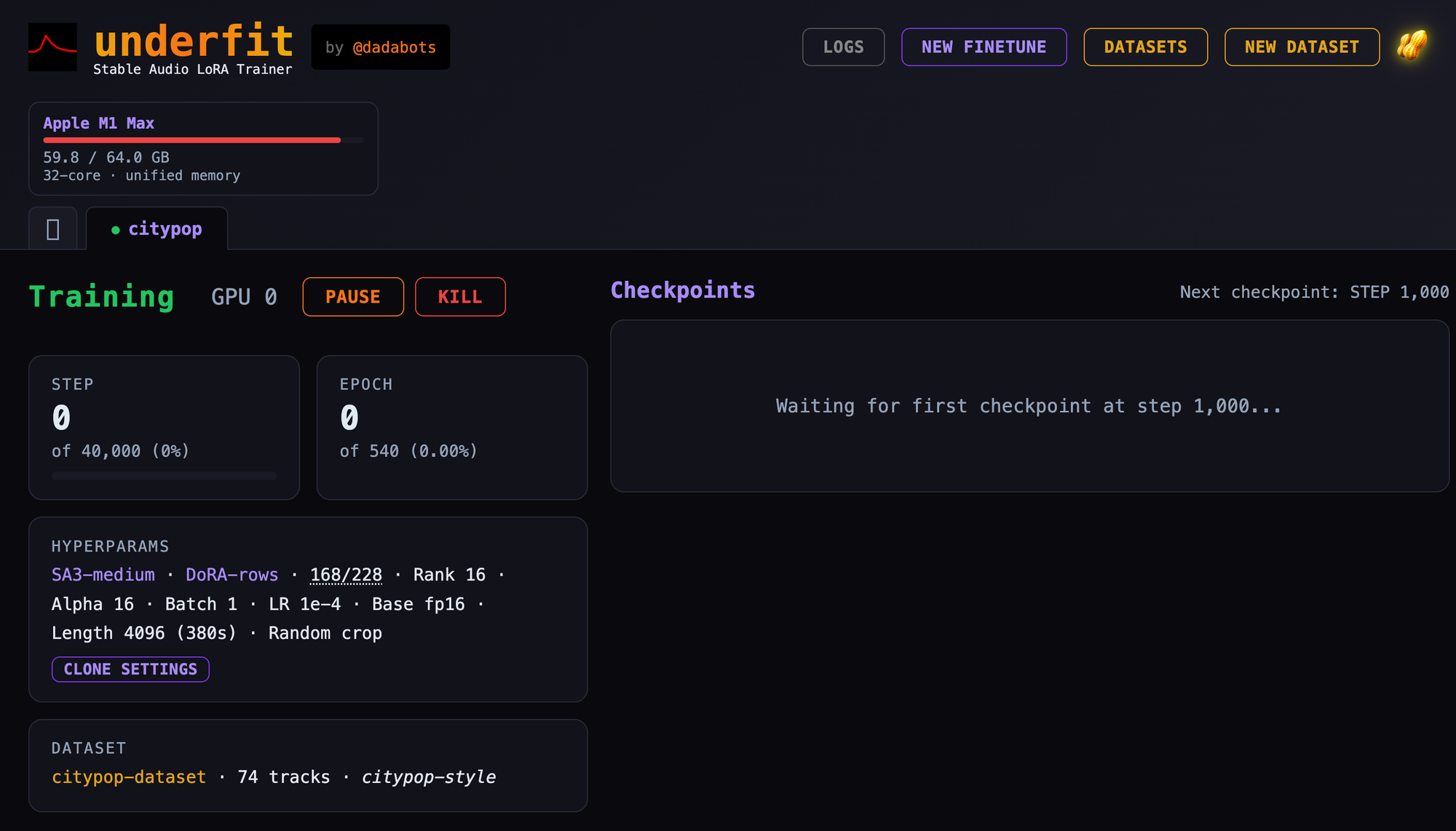
Browser-based AI audio DAW for Stable Audio 3 with text-to-audio, inpainting, LoRA training, FFmpeg effects, waveform editing, sequencer, piano roll, and persistent library. https://github.com/gantasmo/stabledaw
Describe an image, get a 100% schema-valid Ideogram 4 JSON prompt — generated fully locally with an embedded llama.cpp (no Ollama or LM Studio required).
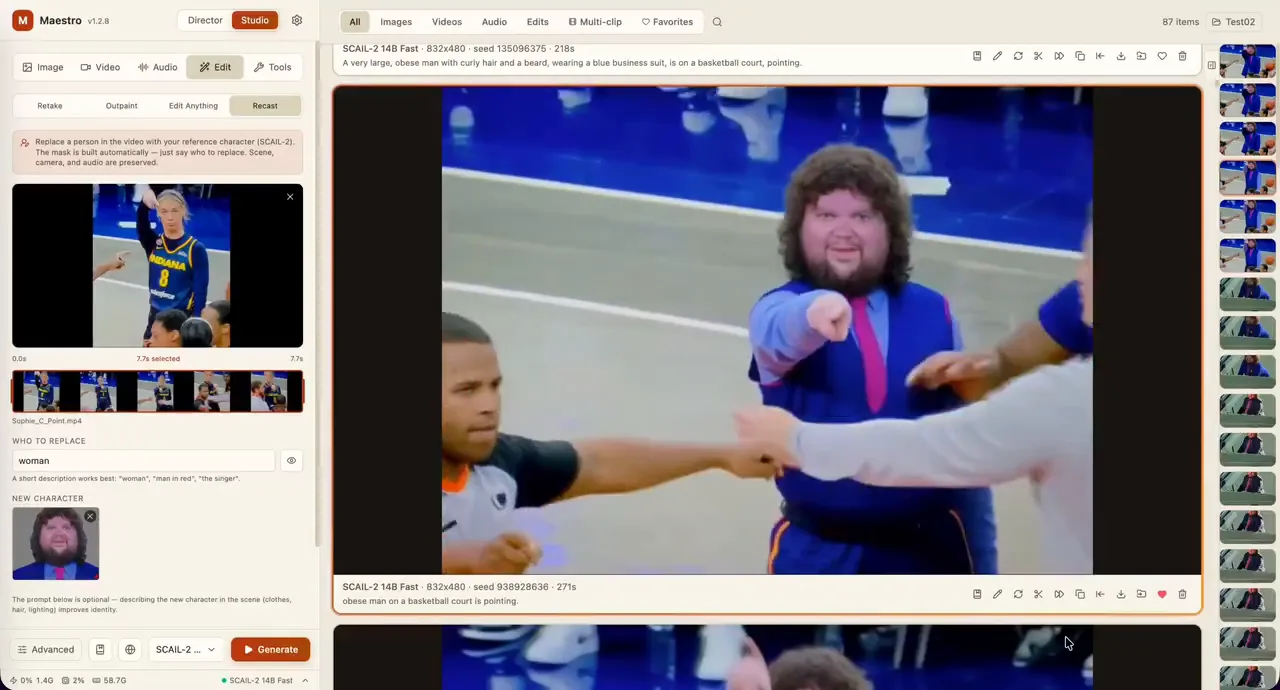
Video translation & dubbing with voice cloning — 100% local, zero API. Supports 30 languages (VoxCPM 2) with per-language CPS calibration, automatic transcription, translation, and AI dubbing.


 @manatheturipa
@manatheturipa @finrandojin
@finrandojin

 42 check-ins
42 check-ins

 5 check-ins
5 check-ins @cocktailpeanut
@cocktailpeanut

 21 check-ins
21 check-ins



