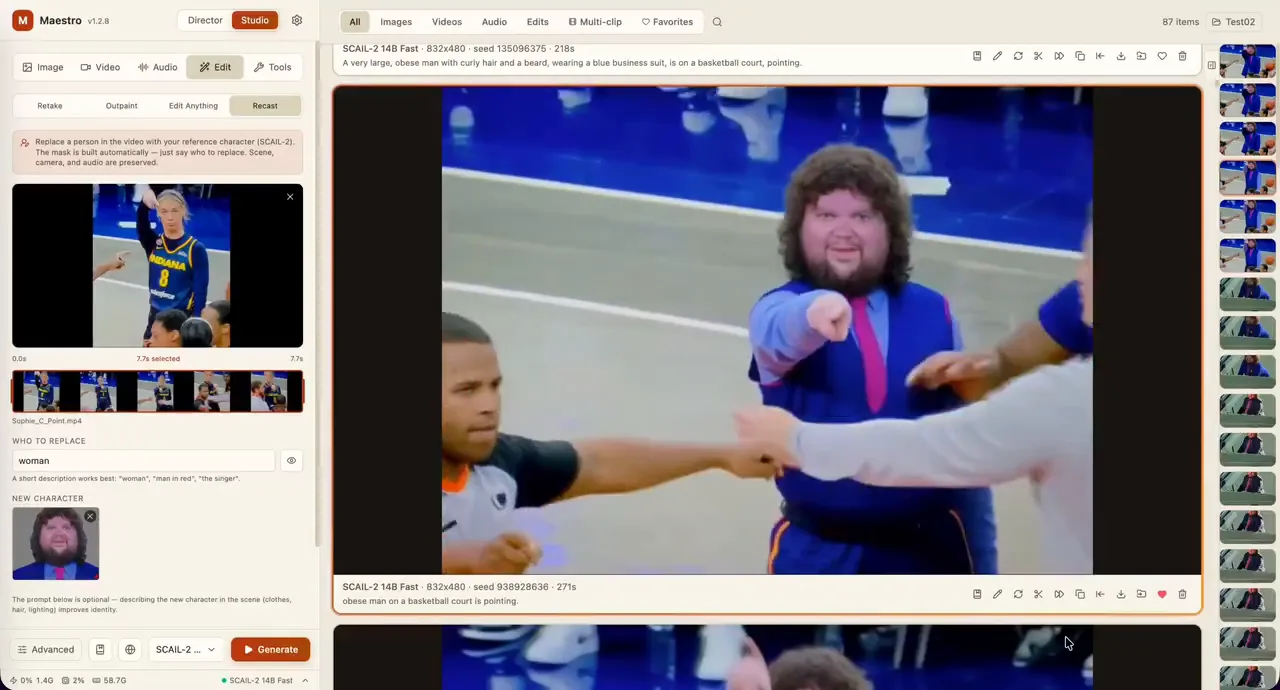
Upload one or more photos and type a short edit instruction (e.g., “add a cat” or “change the sky to sunset”). The app can first rewrite your prompt to make it clear, then uses a fast AI model to a...
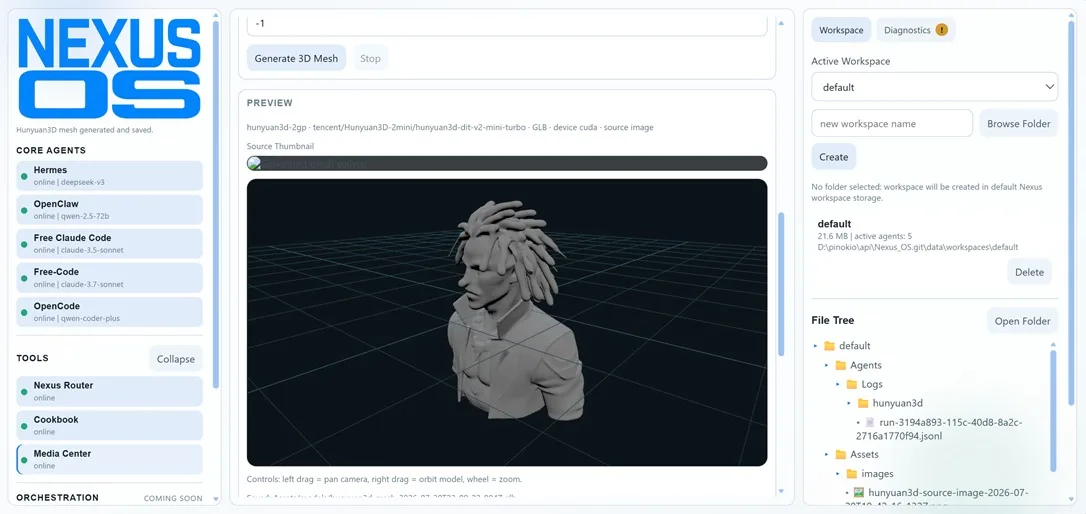
a state-of-the-art open-source model for fast feedforward 3D reconstruction from a single image, developed in collaboration between Tripo AI and Stability AI. https://huggingface.co/spaces/stabilityai/TripoSR
首家工业级全流程 AI 影视生产平台。Industry-first professional AI Agent platform for controllable film & video production. From shorts to live-action with Hollywood-standard workflows.


 @cocktailpeanut
@cocktailpeanut @franzipol
@franzipol
 5 check-ins
5 check-ins

