
Over the past several updates, I’ve been working through community reports and taking a closer look at how TT...
Launcher updates
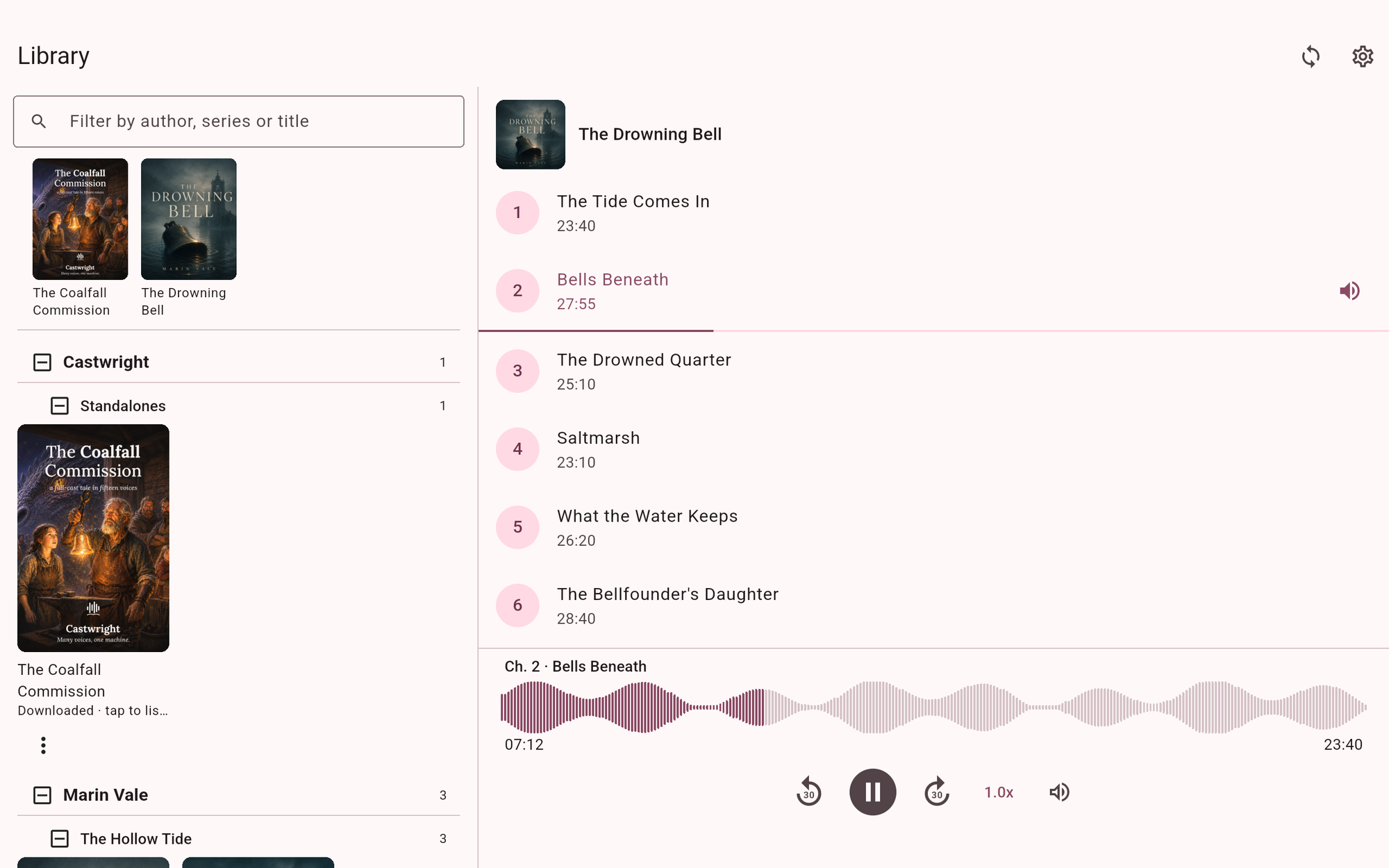
Castwright v1.14.0 — Chinese and Japanese join the cast, and the app grows up on tablets
Quick recap for anyone new: Castwright turns a book into a full-cast audiobook — every character in its own v...
ComfyUI Installer v1.2 — Multiple Instances, GPU Selection and Improved Restarts

🚀 ComfyUI Installer v1.2 — Multiple Instances, GPU Selection and Improved Restarts The Inteliweb AI ComfyUI ...

Remix mode: drop your trained face into ANY scene - 100% on your Mac

Phosphene's new Remix mode fuses two things into a single local render: 1) a Character you trained - a LoRA o...
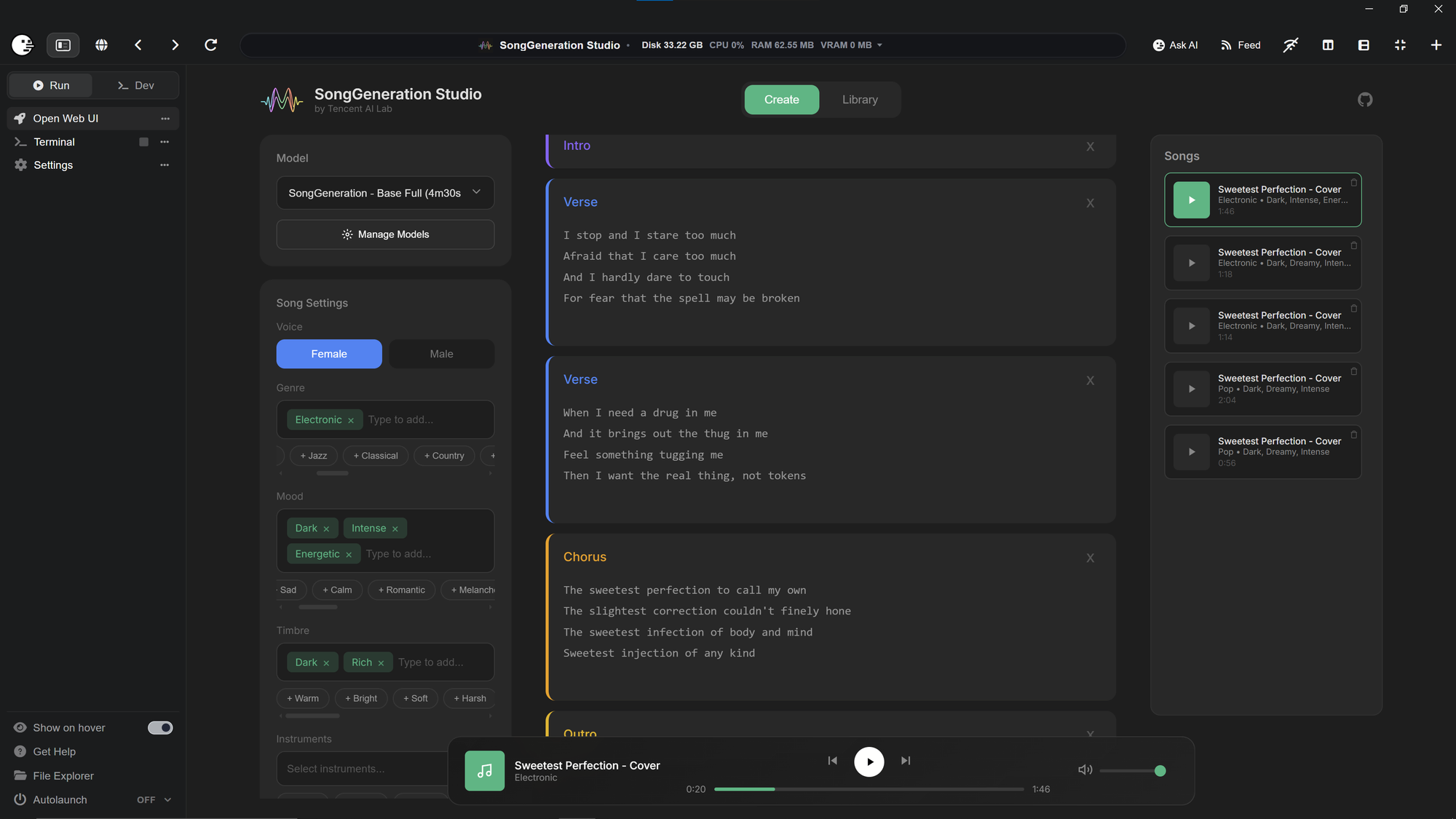
Songgeneration - Fixed

You may have noticed that all Pinokio installer of SongGeneration-Studio and SongGeneration stopped working. ...
Store
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
OpenAI-compatible Speech-to-Text and Text-to-Speech server. Powered by Faster-Whisper, Kokoro, and Piper.
Practical human video matting framework that preserves fine details. Drop your video, assign target masks with a few clicks, and get foreground/alpha matting results.

We’re on a journey to advance and democratize artificial intelligence through open source and open science.
A fully local, cross-platform audio visualizer editor. Create reactive music videos with layered graphics, AI-transcribed lyrics, and frame-perfect MP4 exports — all running in your browser
 @theawakenone2 check-ins
@theawakenone2 check-insThe official JavaScript (Node) library for the ElevenLabs API.
Upload an MP3, WAV, or OGG file and instantly apply vintage 80s‑90s effects, pitch/formant voice changes, and preset styles. You can preview the result in the player and download the processed trac...
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Pinokio launcher for the MLX-only SongGeneration Studio.
MLX-Video-TranscriptionFeatured
[Mac Only] Super Fast MLX Powered Video Transcription https://github.com/RayFernando1337/MLX-Auto-Subtitled-Video-Generator/ by https://x.com/RayFernando1337

Get up and running with Kimi-K2.5, GLM-5, MiniMax, DeepSeek, gpt-oss, Qwen, Gemma and other models.

Voice Cloning, Now Inside Kokoro. Generate natural multilingual speech and clone any target voice with ease.
On-device TTS model by Neuphonic
金融团队(A股版):多Agent投研决策系统,深度改造自 virattt/ai-hedge-fund。
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.