Project updates

Latest Master Branch
Fork from https://github.com/facefusion/facefusion-pinokio Which always installs / Updates to the latest Mast...
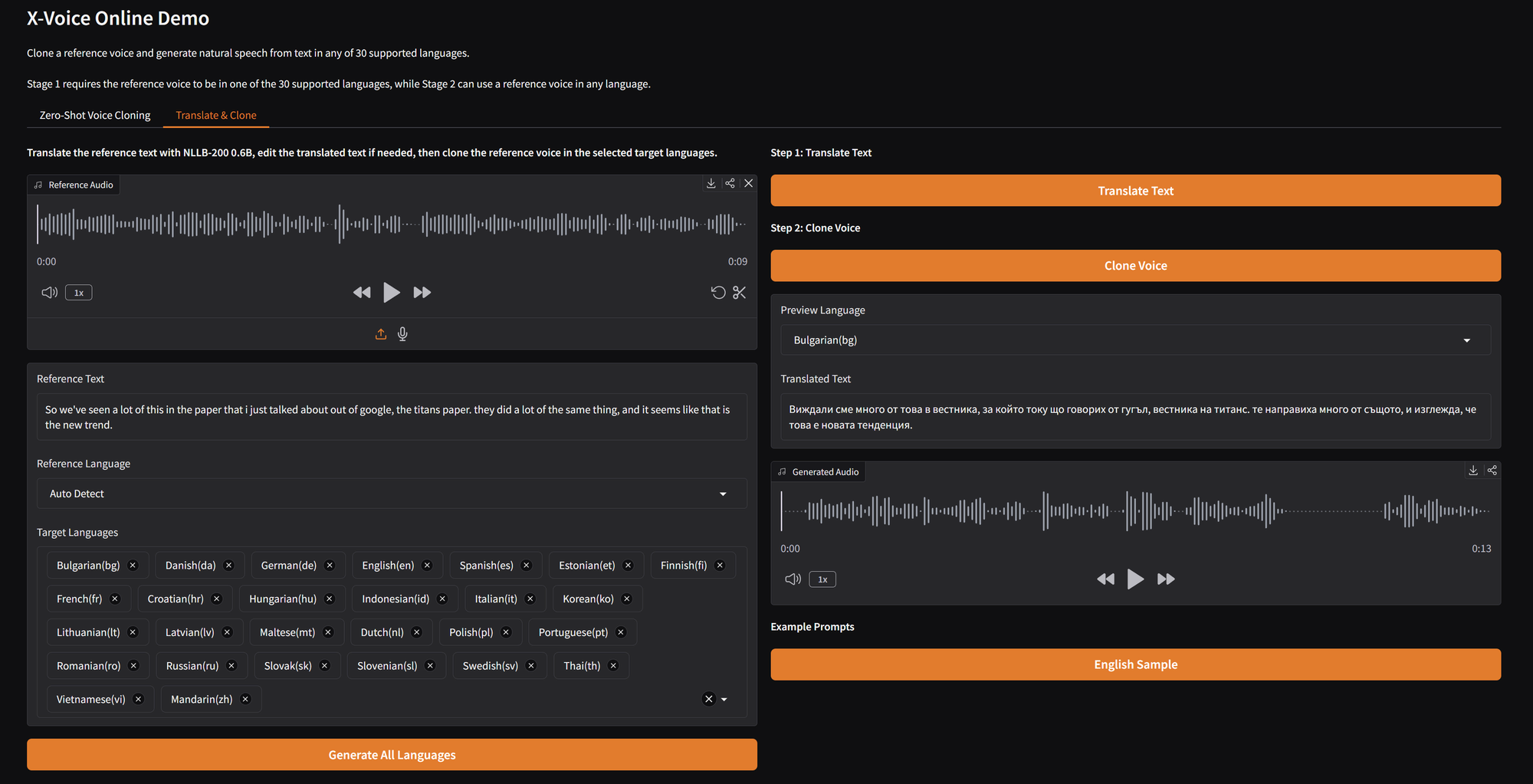
X-Voice The universal translator
X-Voice is a voice clone app that lets you clone voices in any language. The Zero-Shot Voice Cloning tab work...
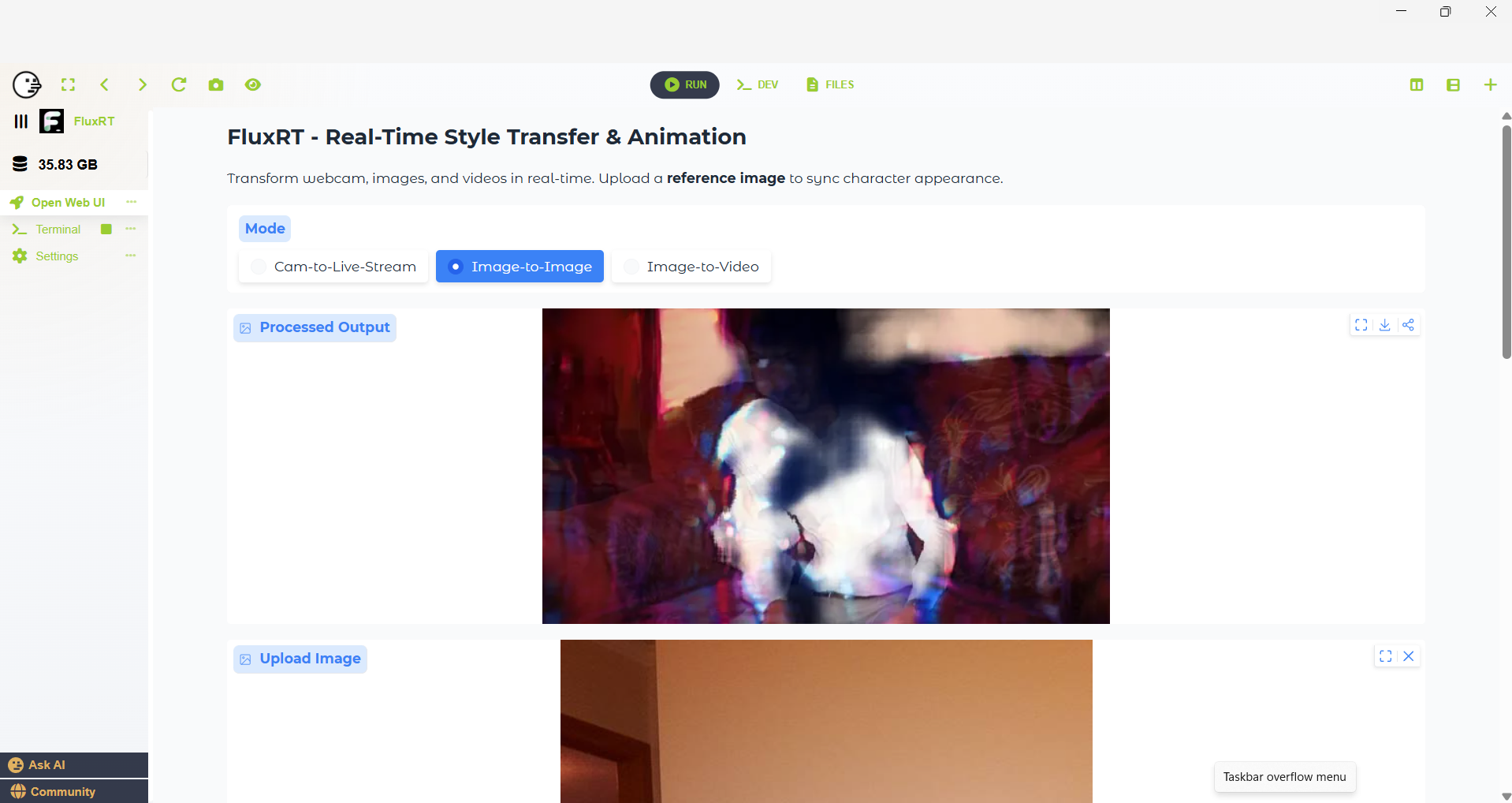

I’ve completed a full installer for FluxRT and have already integrated several new modes into the UI, includi...
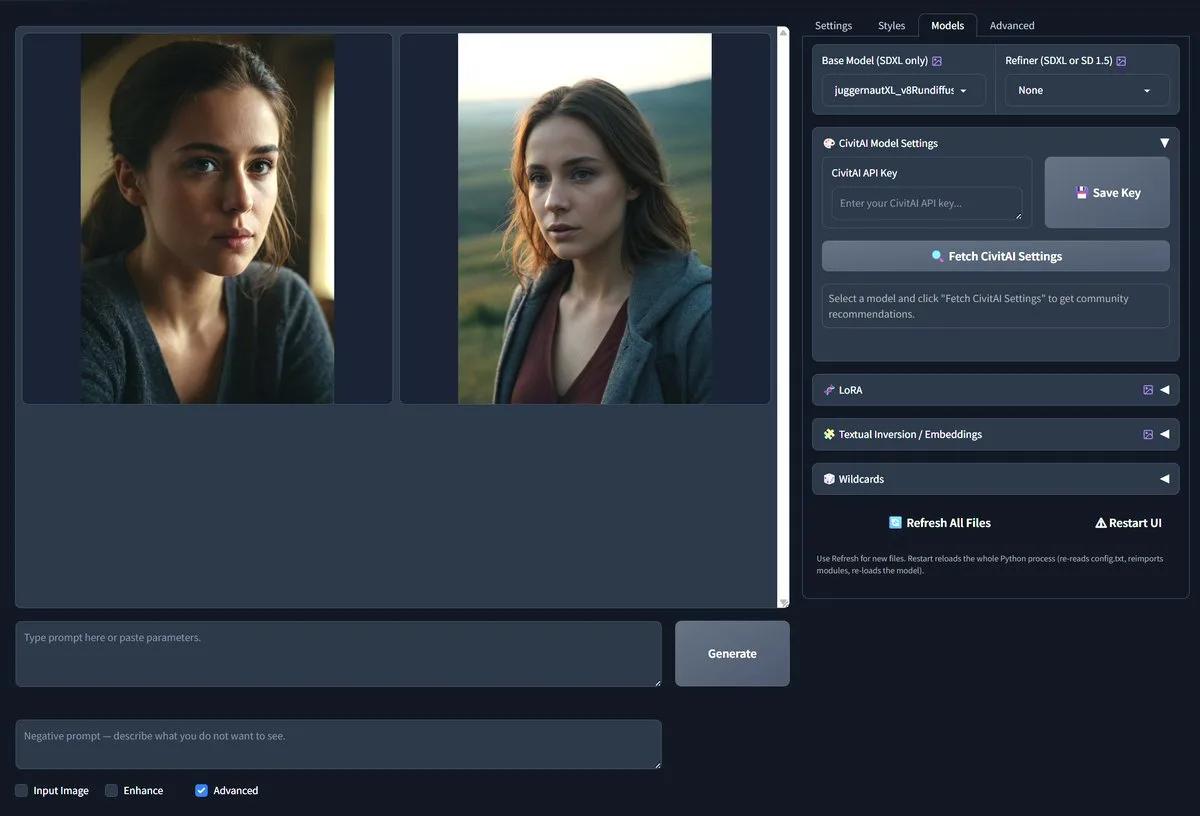
Fooocus2026 — Pinokio launcher available now
A one-click way to install my fork of Fooocus 2.5.5, with the quality-of-life additions I kept missing in ups...
Store

MLX-Video-TranscriptionFeatured
[Mac Only] Super Fast MLX Powered Video Transcription https://github.com/RayFernando1337/MLX-Auto-Subtitled-Video-Generator/ by https://x.com/RayFernando1337
facepokeFeatured
[NVIDIA Only] Select a portrait, click to move the head around https://github.com/jbilcke-hf/FacePoke
diamondFeatured
Diffusion for World Modeling https://diamond-wm.github.io/
dittoFeatured
the simplest self-building coding agent https://github.com/yoheinakajima/ditto
omnigenFeatured
A unified image generation model that you can use to perform various tasks, including but not limited to text-to-image generation, subject-driven generation, Identity-Preserving Generation, and image-conditioned generation. https://huggingface.co/spaces/Shitao/OmniGen
Allegro-txt2vidFeatured
[NVIDIA ONLY] Generate videos with Allegro txt2vid model https://github.com/rhymes-ai/Allegro
MFLUX-WEBUIFeatured
[MAC ONLY] A powerful and user-friendly web interface for FLUX, powered by MLX and Gradio via MFLUX
HallucinatorFeatured
[NVIDIA ONLY] Autocomplete any voice(s), powered by Hertz AI (Standard Intelligence)

InstantIRFeatured
restore low-res images, restore broken images, recreate a new version of the image with a prompt https://huggingface.co/spaces/fffiloni/InstantIR
RMBG-2-StudioFeatured
Enhanced background remove and replace app built around BRIA-RMBG-2.0 https://huggingface.co/briaai/RMBG-2.0

pyramidflowFeatured
Pyramd Flow Video Generation AI (text-to-video & image-to-video) https://github.com/jy0205/Pyramid-Flow
Clarity Refiners UIFeatured
An enhanced local port of finegrain-image-enhancer powered by Refiners (https://huggingface.co/spaces/finegrain/finegrain-image-enhancer), which was adapted from philz1337x's Clarity Upscaler (https://github.com/philz1337x/clarity-upscaler)


 5 check-ins
5 check-insechomimic2Featured
[NVIDIA ONLY] Make virtual avatars talk whatever you want with an image and an audio clip https://github.com/antgroup/echomimic_v2
ai-video-composerFeatured
The ultimate video editor powered by natural language and FFMPEG https://huggingface.co/spaces/huggingface-projects/ai-video-composer

MMAudioFeatured
Generate synchronized audio from video and/or text inputs https://github.com/hkchengrex/MMAudio
StyleTTS2 StudioFeatured
Build your own voice for StyleTTS2
bolt.diyFeatured
Prompt, run, edit, and deploy full-stack web apps. https://github.com/stackblitz-labs/bolt.diy
Open WebUIFeatured
User-friendly WebUI for LLMs, supported LLM runners include Ollama and OpenAI-compatible APIs https://github.com/open-webui/open-webui

 15 check-ins
15 check-insYuEFeatured
[NVIDIA ONLY] YuEGP--A Web UI for YuE, an Open Full-song Generation Foundation Model (10G VRAM required), via https://github.com/deepbeepmeep/YuEGP