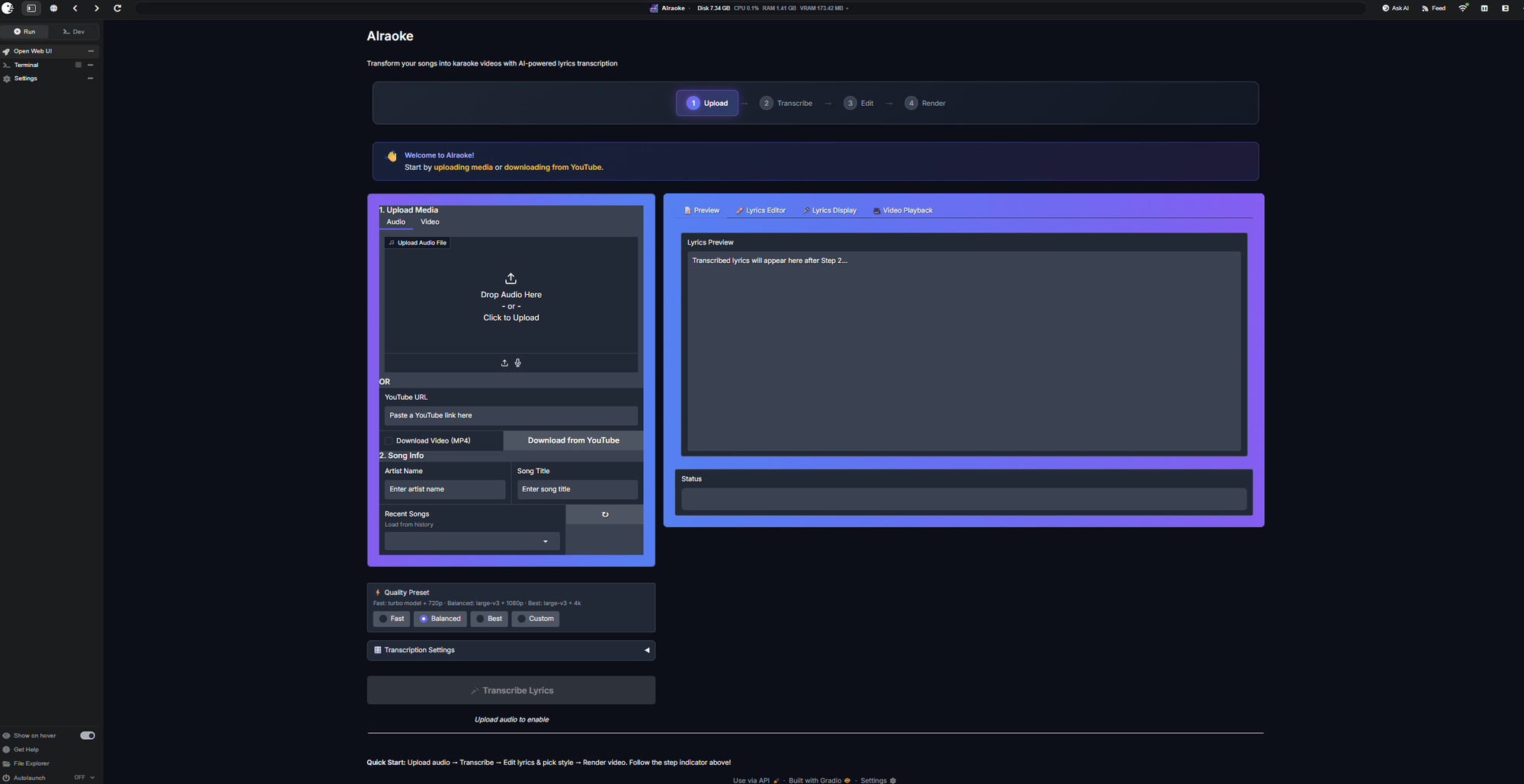
AIraoke@theawakenone•49 min agoAIraoke just got a glow-up 🎤Just pushed an update to AIraoke-Pinokio. - Guided workflow, quality presets - YouTube download support - Cus...
PhospheneFeatured@bizarro•4h agoPhosphene 3.2.7 - fixes, mostly from bugs you reported herev3.2.7 is out, and it is entirely fixes - most of them from reports posted right here on this board. Hit Upda...
VideoPolish-er@c0m3b4ck•22h agoReleased!Another of my video time-saving apps. Features include: cutting out silence, cutting out stutters, automatic ...
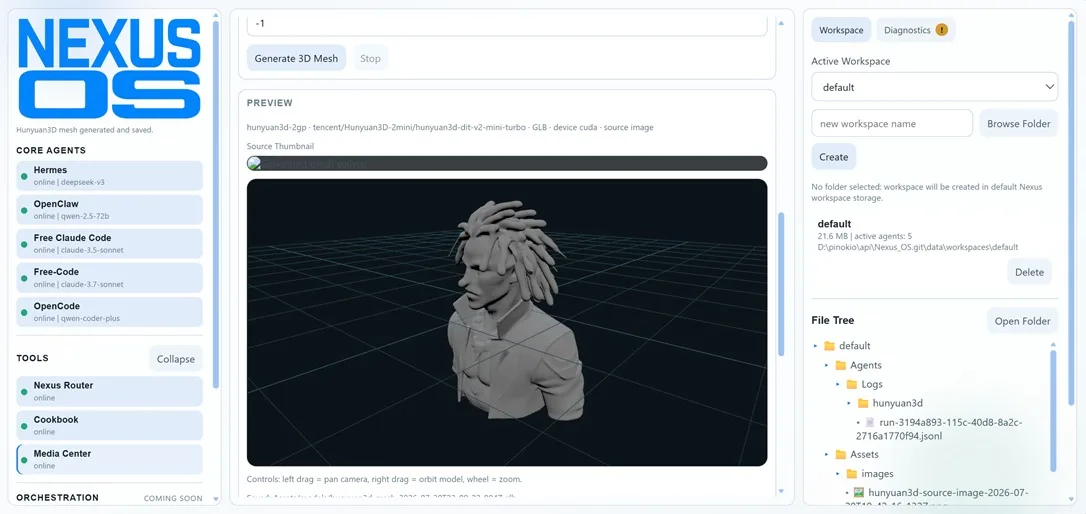
NEXUS OS@ramshi•2d ago3D Model Generation ImplementedFirst steps to get 3D model generation working on Nexus OS. Still more work to be done on it, but it's a step...
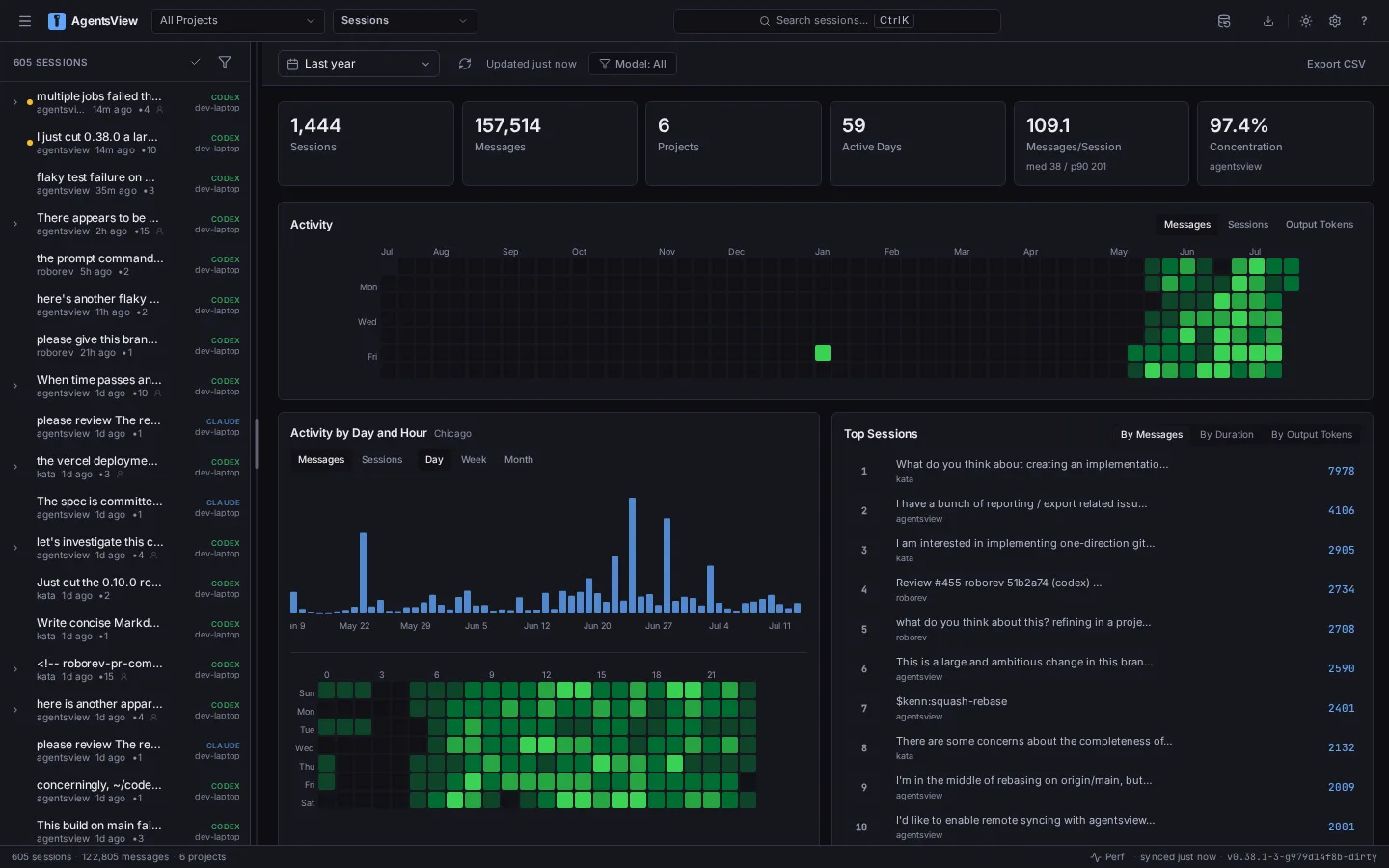
AgentsViewFeatured@cocktailpeanut•4d agoAgentsView: View all your AI agent history in one place.AI coding agents are great at moving work forward. Remembering where that work happened is harder. A useful f...


 @morpheus
@morpheus




