
Wanted TTS of an old 60s manual? Or maybe a handwritten poem? Thanks to the addition of pytesseract to the pr...
Launcher updates
AgentsViewFeatured

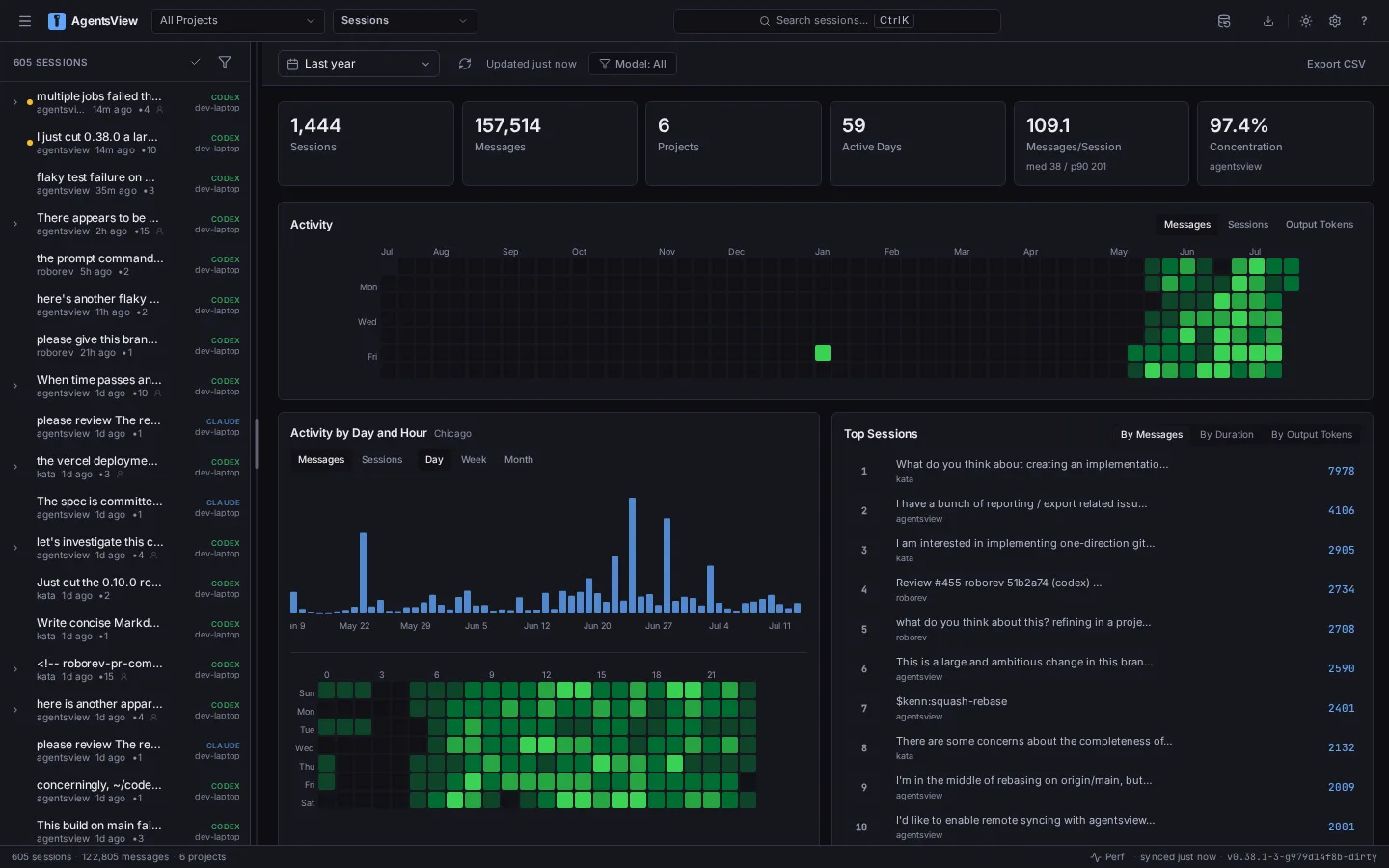
AI coding agents are great at moving work forward. Remembering where that work happened is harder. A useful f...
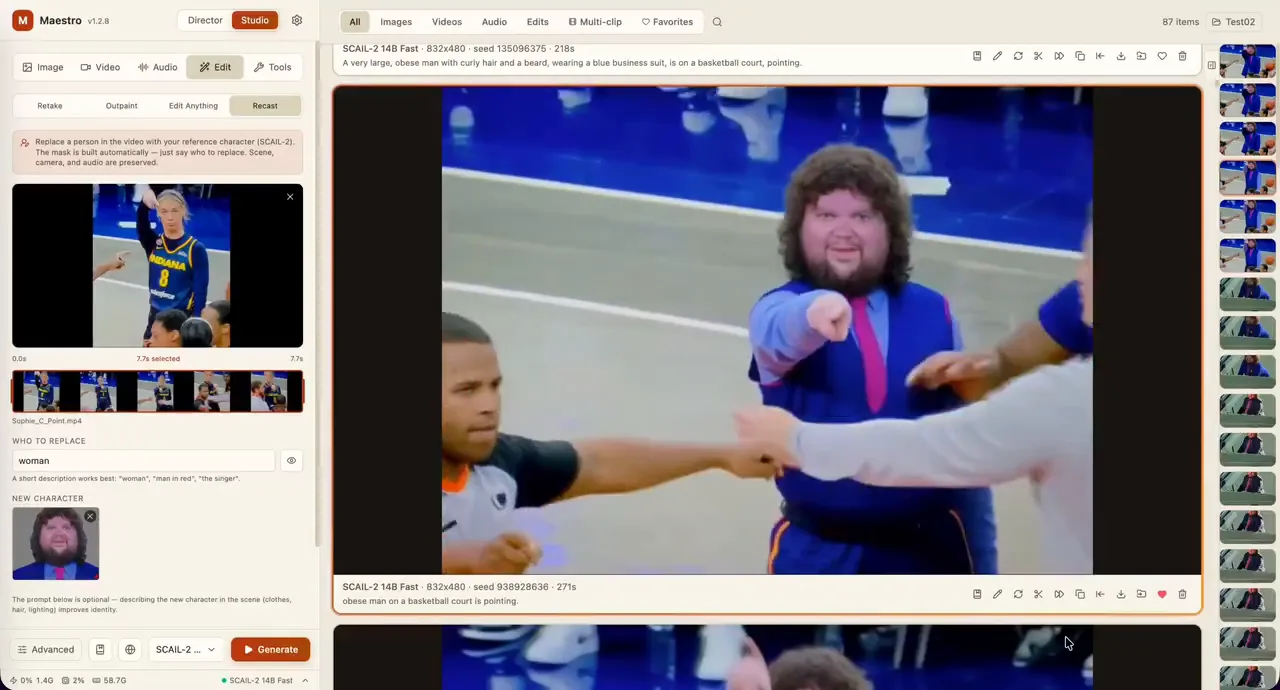
Maestro v1.3.0 is out: SCAIL-2 character animation, 100% LOCAL, FREE & EASY!

(NEW) "Recast": swap anyone in a video for your own character. Drop a clip, type who to replace ("the woman",...


Wan2GP - AMDFeatured
Formerly, if someone had an IGPU and a dedicated GPU from AMD, the GPU detection failed. Pinokio 8 allows us ...
Store
Gradio-based web interface for the LuxTTS voice cloning and text-to-speech model, enabling users to generate customized speech from text using uploaded or recorded audio references with adjustable parameters like speed, guidance scale, and inference steps.
 @theawakenone2 check-ins
@theawakenone2 check-insOneTrainer para Pinokio vato loco
Imposing Consistent Light - Control lighting of images
Fast AI Video Generation per GPU poor (Wan2.1, Hunyuan, LTV). Gradio UI su http://127.0.0.1:7860


 64 check-ins
64 check-insStable Diffusion WebUI Forge is a platform on top of Stable Diffusion WebUI (based on Gradio) to make development easier, optimize resource management, and speed up inference. https://github.com/Panchovix/stable-diffusion-webui-reForge
DreamID-V: Bridging the Image-to-Video Gap for High-Fidelity Face Swapping via Diffusion Transformer
Google's official AI agent for your terminal. Access Gemini 2.5 Pro with 1M token context window directly from the command line.



Mon portail IA personnel
Secure Workflow Automation for Technical Teams
Relight any image using AI (SwitchLight-inspired)



🦙 Let 2 models debate about a topic you pick. Create custom Ollama models with your own system prompts and parameters and use them to debate ot publish on ollama.com Easy-to-use Gradio interface for building personalized AI models with temperature control and custom instructions.
 @morpheus1 check-in
@morpheus1 check-inVideo Matting with complete cross-platform support for Windows, macOS, and Linux
supirFeatured
[NVIDIA ONLY] Text-driven, intelligent restoration, blending AI technology with creativity to give every image a brand new life https://supir.xpixel.group
 1 check-in
1 check-inbrowser-useFeatured
Run AI Agent in your browser. https://github.com/browser-use/web-ui
Self-hosted Whisper API for Open WebUI
 @manatheturipa4 check-ins
@manatheturipa4 check-insLocal AI Workstation