Alchemist-Production/alexandria-audiobookv5.0updated 2mo ago
A tool that takes a text document containing a book or a novel, ingests it with an LLM to produce an annotated script, and then uses a TTS API to generate the voice lines, finally stitching them together into an audiobook in MP3 format.
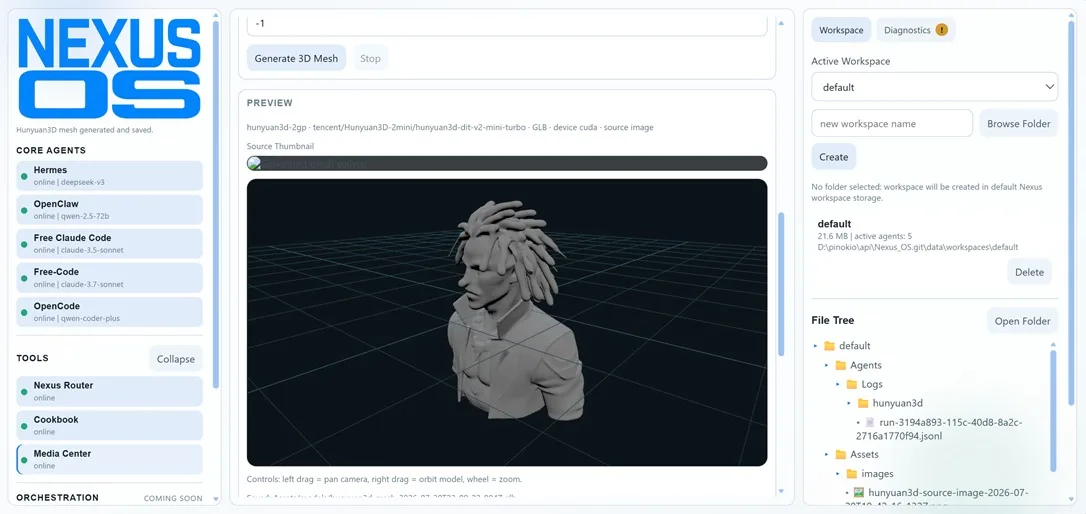
Super Optimized Gradio UI for AI video creation for GPU poor machines (6GB+ VRAM). Supports Wan 2.1/2.2, Qwen, Hunyuan Video, LTX Video and Flux. https://github.com/deepbeepmeep/Wan2GP
drago87/SillyTavern-Character-Generatorv4.0updated 2mo ago
# SillyTavern Character Generator
A pinokio script for https://github.com/Tremontaine/character-card-generator
When used with KoboldCPP use http://localhost:5001/v1
Where 5001 is the port reported by KoboldCPP when starting
Text API Key needs to be filled with anything. (If left empty will give a error so just add anything to it)
[v0.5.1] FramePack Video App offering multiple generation types: Original, F1, video extension, end frame. Features include: LoRA support, job queueing, advanced timestamped prompts, offline mode, a post-processing suite including upscaling, interpolation, filters and more!
Agnuxo1/the-living-agent-pinokiov3.7updated 2mo ago
Autonomous 16x16 Chess-Grid research agent (KoboldCPP + Qwen GGUF). Walks a grid of Markdown knowledge cells, synthesizes short papers, scores novelty, updates a persistent soul.md.

 @cocktailpeanut
@cocktailpeanut

 7 check-ins
7 check-ins @manatheturipa
@manatheturipa
 4 check-ins
4 check-ins





