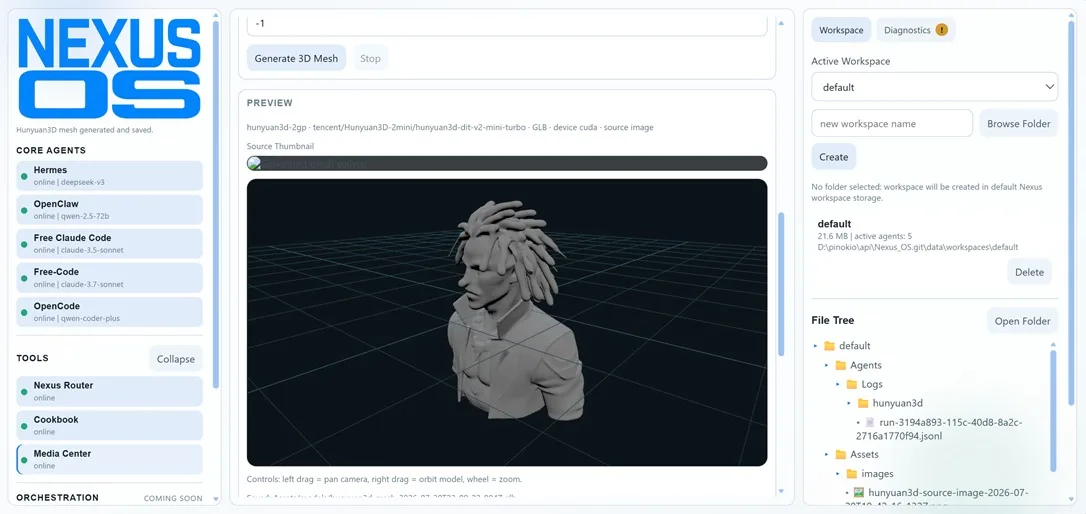
3D Model Generation Implemented

First steps to get 3D model generation working on Nexus OS. Still more work to be done on it, but it's a step...
 @franzipol
@franzipol
 5 check-ins
5 check-ins @cocktailpeanut
@cocktailpeanut
 8 check-ins@cocktailpeanut
8 check-ins@cocktailpeanut

 33 check-ins@morpheus1 check-in@cocktailpeanut1 check-in
33 check-ins@morpheus1 check-in@cocktailpeanut1 check-in






