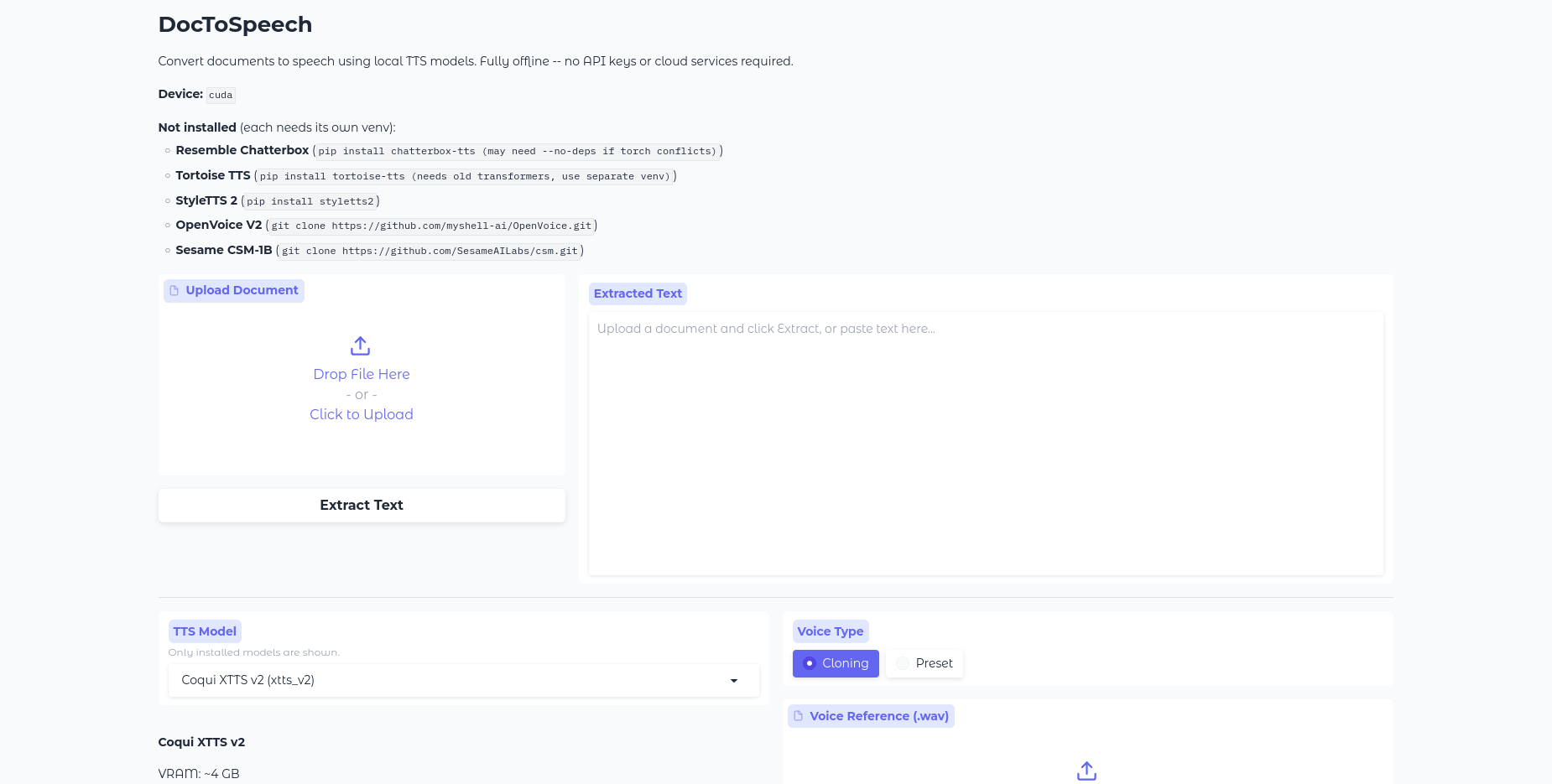

The app is made so that you don't have to go through these annoying online converters to get a text file for ...

 @blizaine
@blizaine

 49 check-ins
49 check-ins @morpheus
@morpheus

 75 check-ins
75 check-ins
 283 check-ins
283 check-ins @sup3rmass1ve
@sup3rmass1ve

 30 check-ins
30 check-ins @cocktailpeanut
@cocktailpeanut
 7 check-ins@cocktailpeanut
7 check-ins@cocktailpeanut 10 check-ins
10 check-ins
 22 check-ins4 check-ins
22 check-ins4 check-ins @anchorite
@anchorite
 22 check-ins
22 check-ins @finrandojin6 check-ins
@finrandojin6 check-ins

 42 check-ins@cocktailpeanut
42 check-ins@cocktailpeanut

 21 check-ins
21 check-ins













