
Another of my video time-saving apps. Features include: cutting out silence, cutting out stutters, automatic ...
Launcher updates
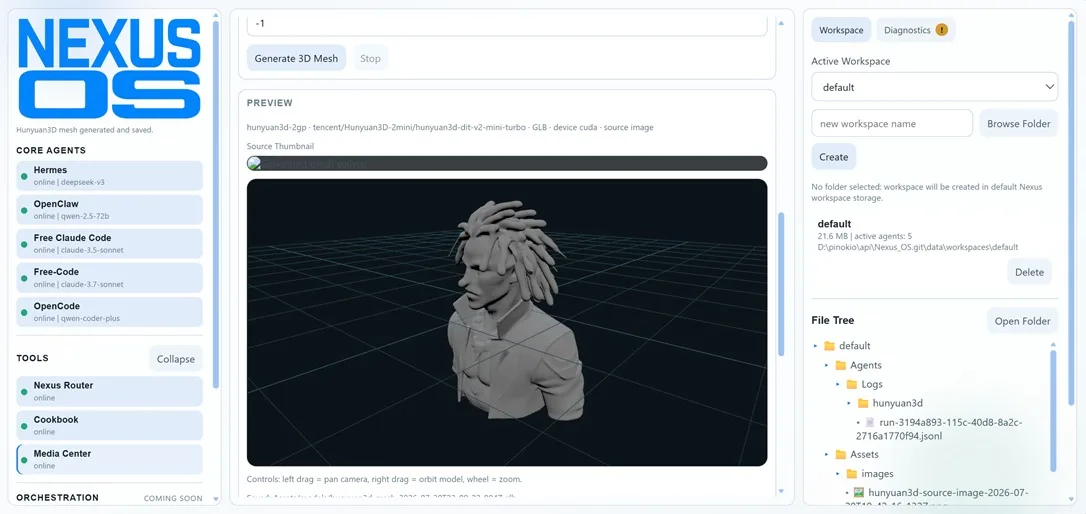
3D Model Generation Implemented

First steps to get 3D model generation working on Nexus OS. Still more work to be done on it, but it's a step...
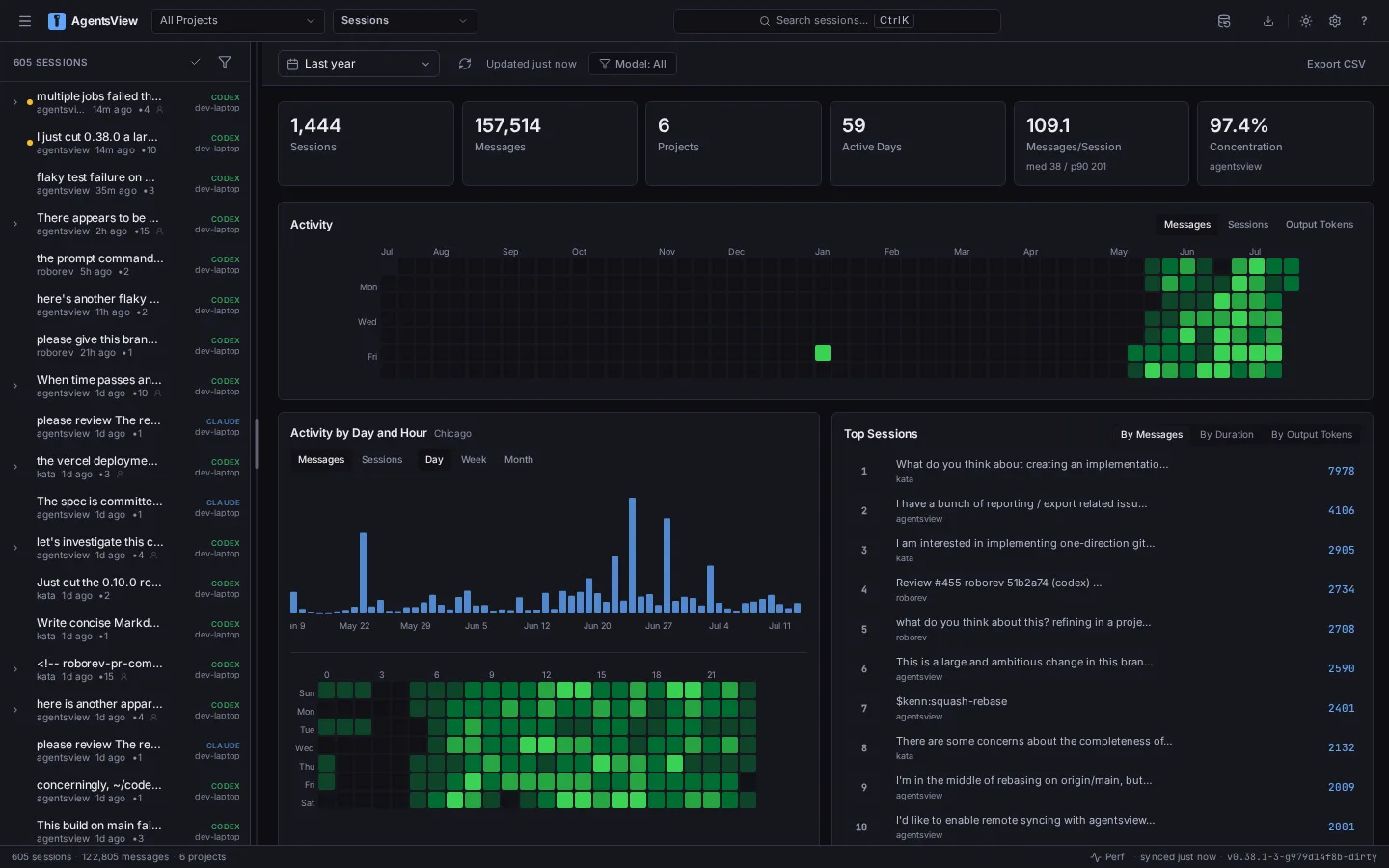
AgentsViewFeatured

AI coding agents are great at moving work forward. Remembering where that work happened is harder. A useful f...
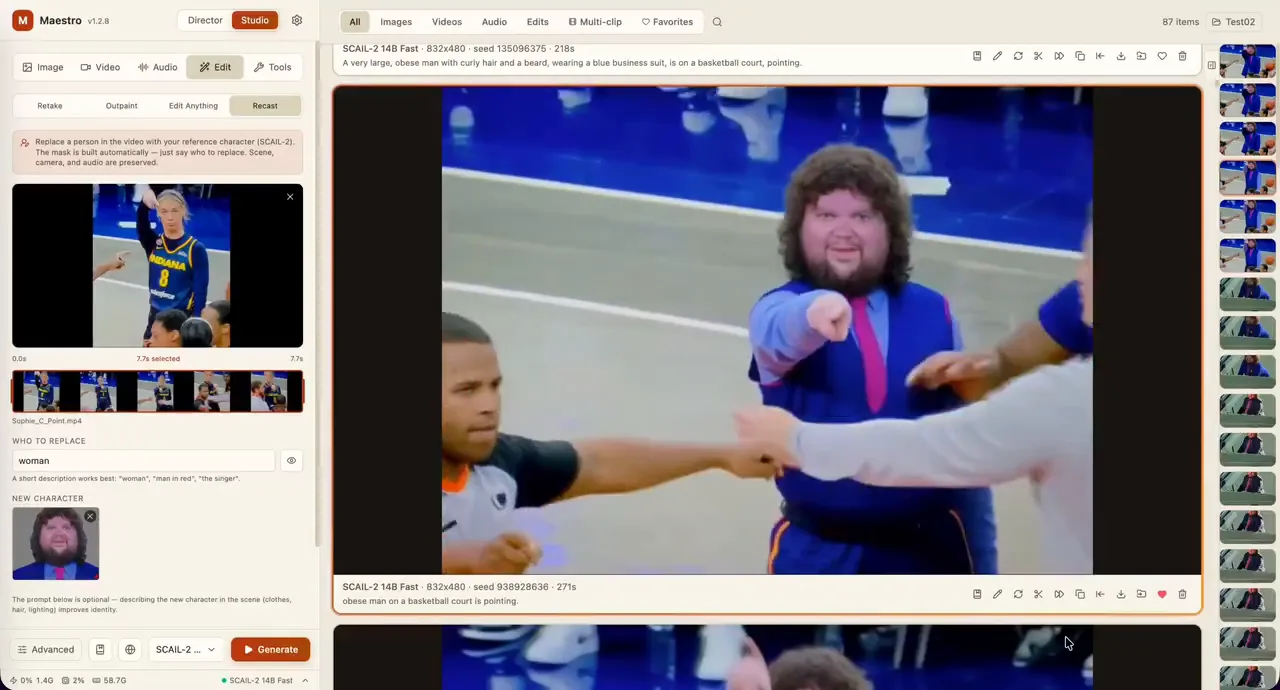
Maestro v1.3.0 is out: SCAIL-2 character animation, 100% LOCAL, FREE & EASY!

(NEW) "Recast": swap anyone in a video for your own character. Drop a clip, type who to replace ("the woman",...

Store
Local/cloud AI YouTube video generator: script, visuals, voiceover, thumbnail, MP4.
Lightricks LTX-2.3 video generation (22B distilled-1.1) with a Gradio UI. Auto-detects GPU and configures offload.


Open-source prompt optimization tool — improve your LLM prompts with AI-powered suggestions and explanations.
A Python CLI and local web UI for stripping audio metadata and applying watermark-disruption research transforms. https://github.com/geeknik/mmm
[Arxiv 2026] ReactiveGWM: Steering NPC in Reactive Game World Models
CLI and library for removing visible (Gemini) and invisible (SynthID, C2PA, EXIF) AI watermarks from images
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
fast image editing using FireRed Image Edit and gr.Server
Desktop Companion for Hermes Agent


We’re on a journey to advance and democratize artificial intelligence through open source and open science.
The open-source reactive database for app developers
A real-time silent speech recognition tool.
Enter a brief description of the website you want, and the app writes the corresponding HTML or React code for you. It shows a live preview of the generated page and lets you download or view the s...
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.