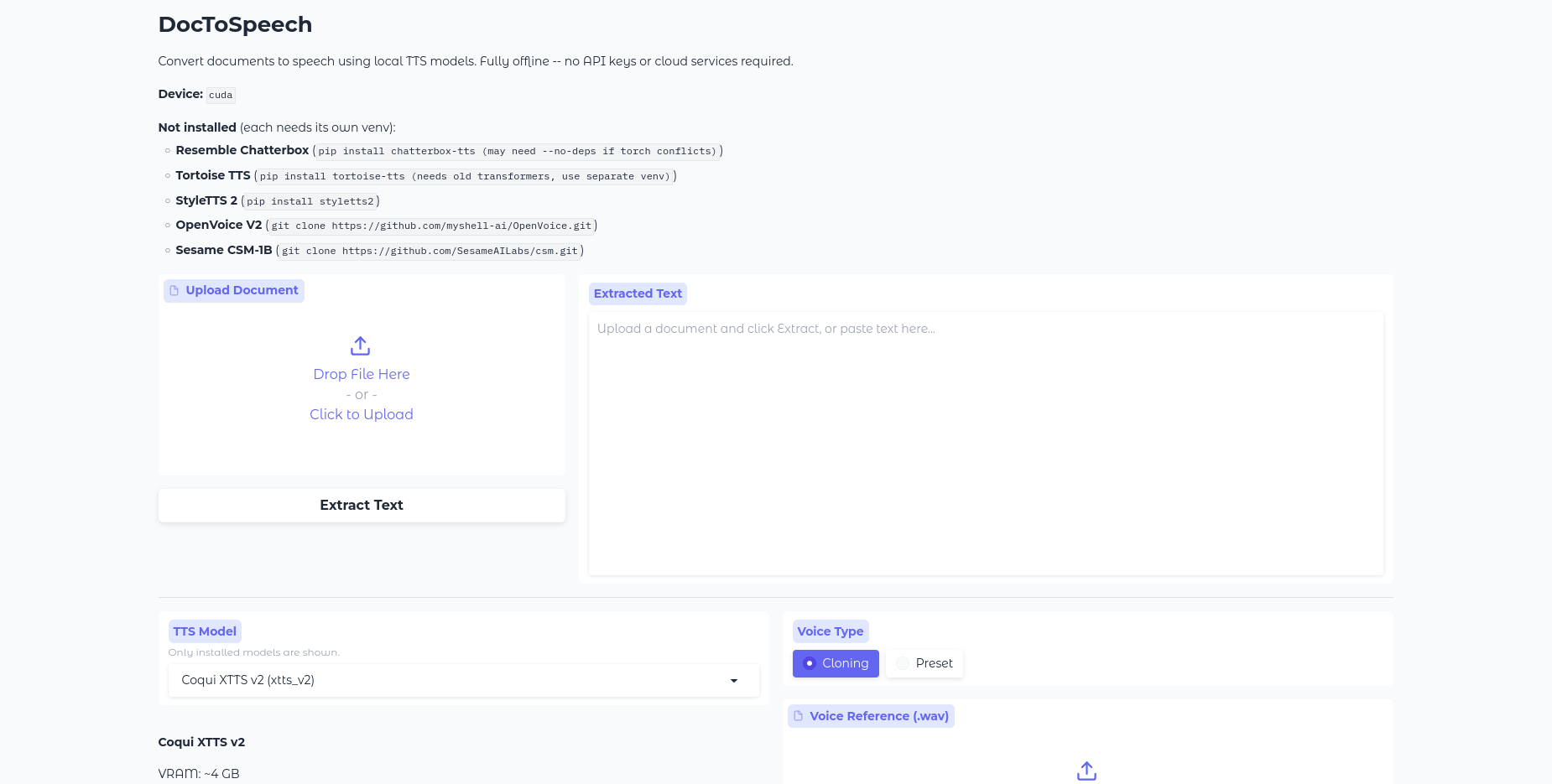
DocToSpeech@c0m3b4ck•4h agoAbout the app - 18-07-2026The app is made so that you don't have to go through these annoying online converters to get a text file for ...
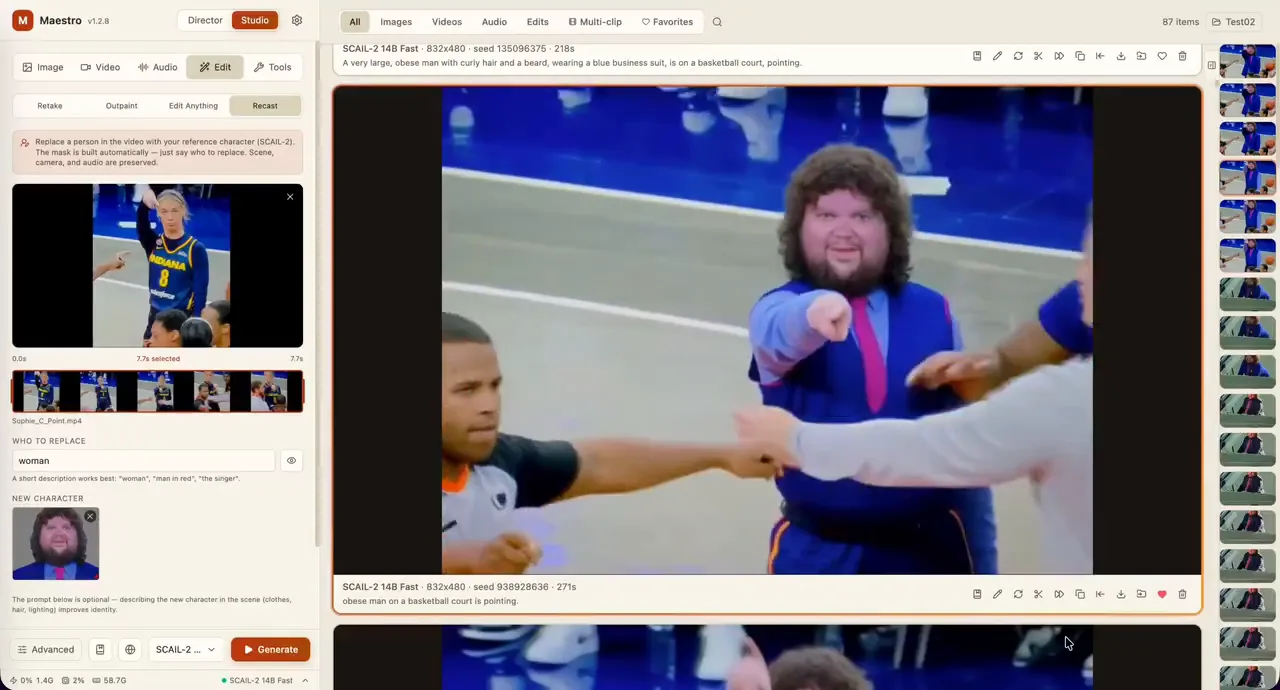
MaestroFeatured@blizaine•15h agoMaestro v1.3.0 is out: SCAIL-2 character animation, 100% LOCAL, FREE & EASY!(NEW) "Recast": swap anyone in a video for your own character. Drop a clip, type who to replace ("the woman",...
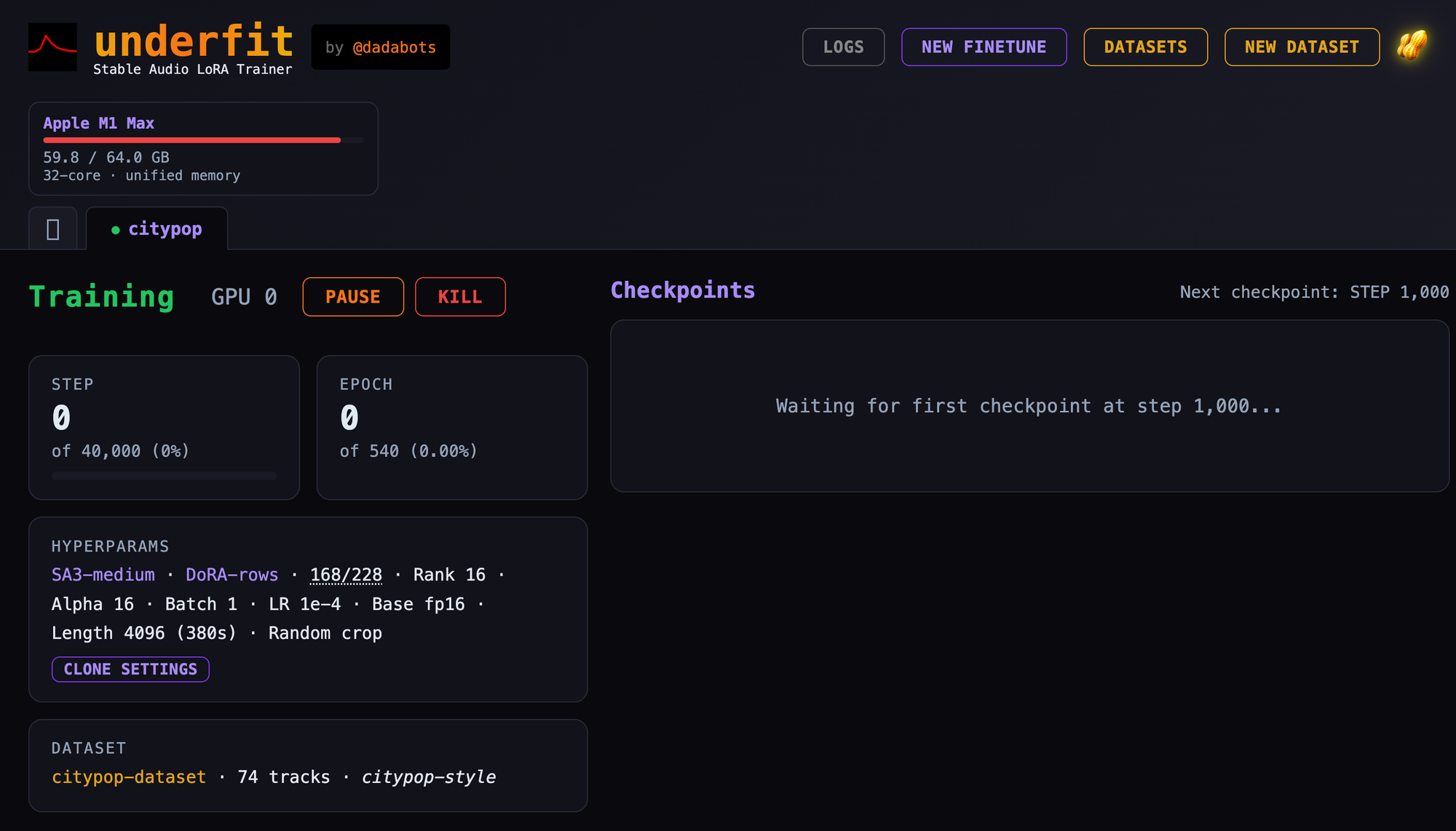
UnderfitFeatured@cocktailpeanut•1d agoTrain StableAudio 3 on your Mac with Underfit!Underfit has shipped MLX support, and now Mac users can train their own StableAudio3 Loras! https://github.co...
Wan2GP - AMDFeatured@morpheus•4d agoImproved GPU detectionFormerly, if someone had an IGPU and a dedicated GPU from AMD, the GPU detection failed. Pinokio 8 allows us ...


 @cocktailpeanut
@cocktailpeanut 2 check-ins
2 check-ins 1 check-in
1 check-in

