
Another of my video time-saving apps. Features include: cutting out silence, cutting out stutters, automatic ...
Launcher updates
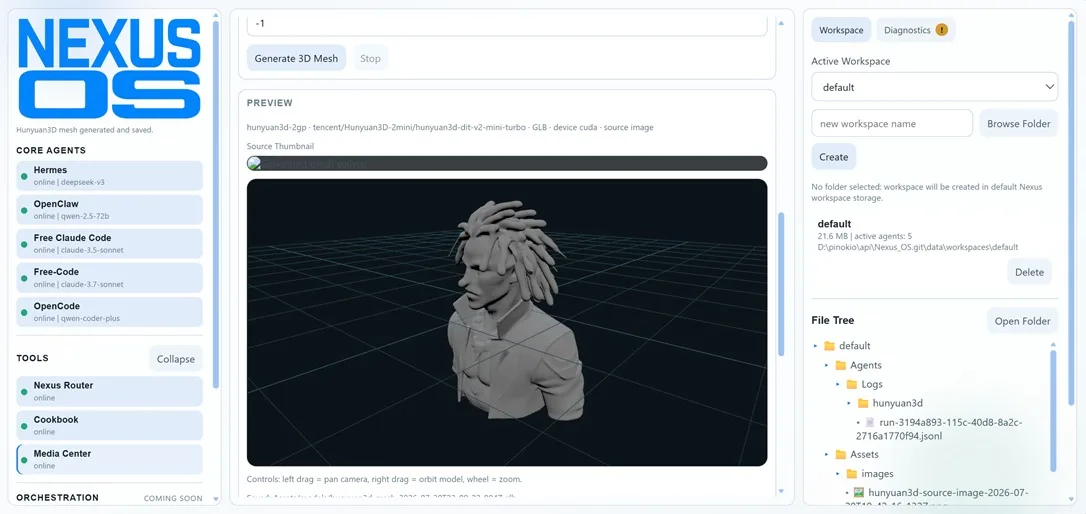
3D Model Generation Implemented

First steps to get 3D model generation working on Nexus OS. Still more work to be done on it, but it's a step...
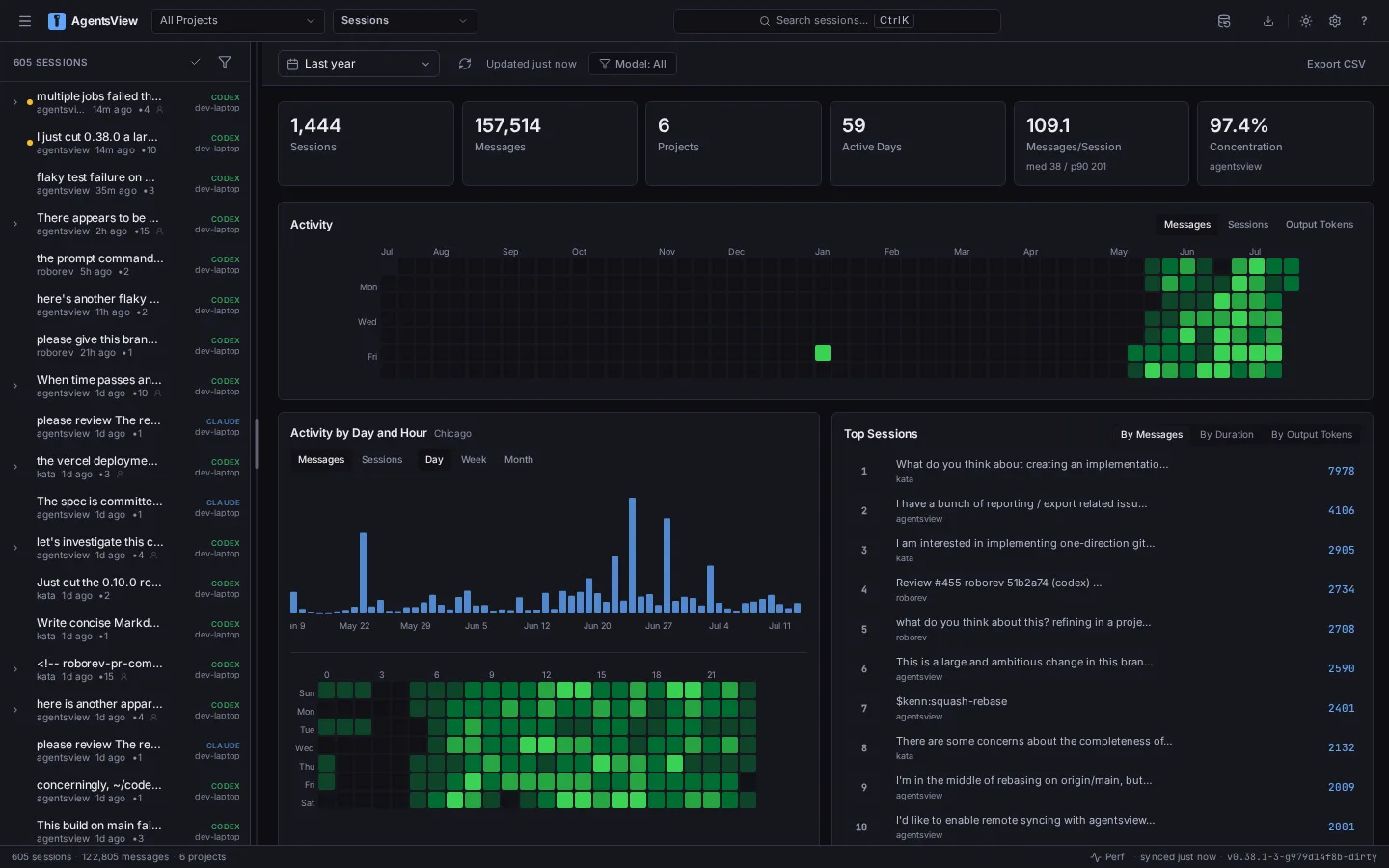
AgentsViewFeatured

AI coding agents are great at moving work forward. Remembering where that work happened is harder. A useful f...
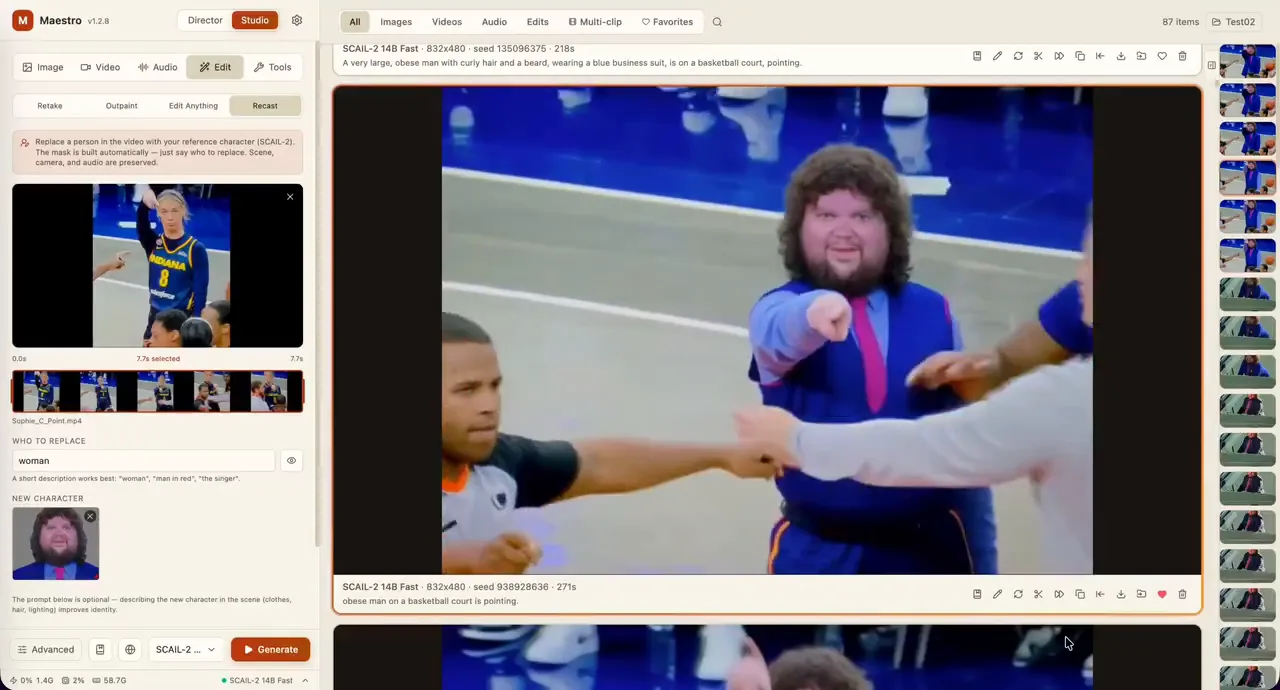
Maestro v1.3.0 is out: SCAIL-2 character animation, 100% LOCAL, FREE & EASY!

(NEW) "Recast": swap anyone in a video for your own character. Drop a clip, type who to replace ("the woman",...

Store
[CVPR'26] Official code for the paper "VGG-T³: Offline Feed-Forward 3D Reconstruction at Scale"
Apple Silicon music generation — MusicGen, Stable Audio Open, Bark.
Sort competition photos into folders by gymnast using AI face recognition.
LUPINE is a GPU over IP bridge allowing GPUs on remote machines to be attached to CPU-only machines.



184 plug-and-play AI agent personas em Português brasileiro — tradução completa do agency-agents
Real-time face swap for PC streaming or video calls
PiD: Fast and High-Resolution Latent Decoding with Pixel Diffusion
Create professional demos and mockups in seconds, directly in your browser
diffusers-image-fillFeatured
Remove objects from an image https://huggingface.co/spaces/OzzyGT/diffusers-image-fill
SCOPE: Simulating Cross-game Operations in Playable Environments for FPS World Models
zonosFeatured
Zonos-v0.1 is a leading open-weight text-to-speech model trained on more than 200k hours of varied multilingual speech, delivering expressiveness and quality on par with—or even surpassing—top TTS providers. https://github.com/Zyphra/Zonos
DiaFeatured
Dia is a 1.6B parameter text to speech model created by Nari Labs. Dia directly generates highly realistic dialogue from a transcript. You can condition the output on audio, enabling emotion and tone control. The model can also produce nonverbal communications like laughter, coughing, clearing throat, etc. https://github.com/nari-labs/dia
Local-first AI avatar video studio powered by duixcom/Duix-Avatar, Docker, and a consent-aware browser studio.
Use claude-code for free in the terminal, VSCode extension or discord like OpenClaw (voice supported)
Turn your PC, Mac, or Linux box into a private AI server. LLM inference, chat UI, voice, agents, workflows, RAG, and image generation.
Contribute to meituan-longcat/LongCat-Video development by creating an account on GitHub.
Native web workspace for Hermes Agent — chat, terminal, memory, skills, inspector.
