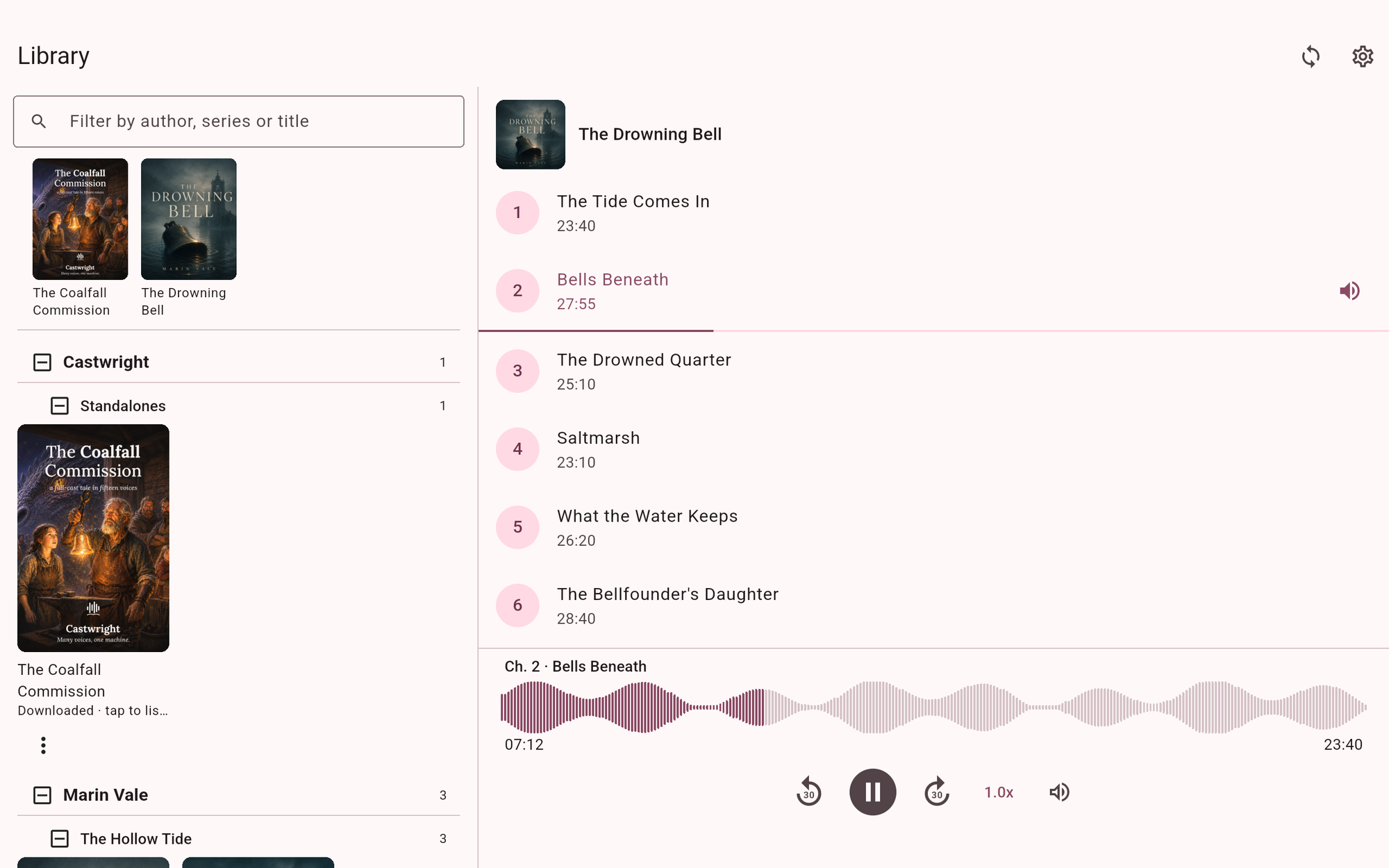
Castwright@dudarenok_maker•9h agoCastwright v1.14.0 — Chinese and Japanese join the cast, and the app grows up on tabletsQuick recap for anyone new: Castwright turns a book into a full-cast audiobook — every character in its own v...
ComfyUI@maoper•1d agoComfyUI Installer v1.2 — Multiple Instances, GPU Selection and Improved Restarts🚀 ComfyUI Installer v1.2 — Multiple Instances, GPU Selection and Improved Restarts The Inteliweb AI ComfyUI ...
PhospheneFeatured@bizarro•2d agoRemix mode: drop your trained face into ANY scene - 100% on your MacPhosphene's new Remix mode fuses two things into a single local render: 1) a Character you trained - a LoRA o...
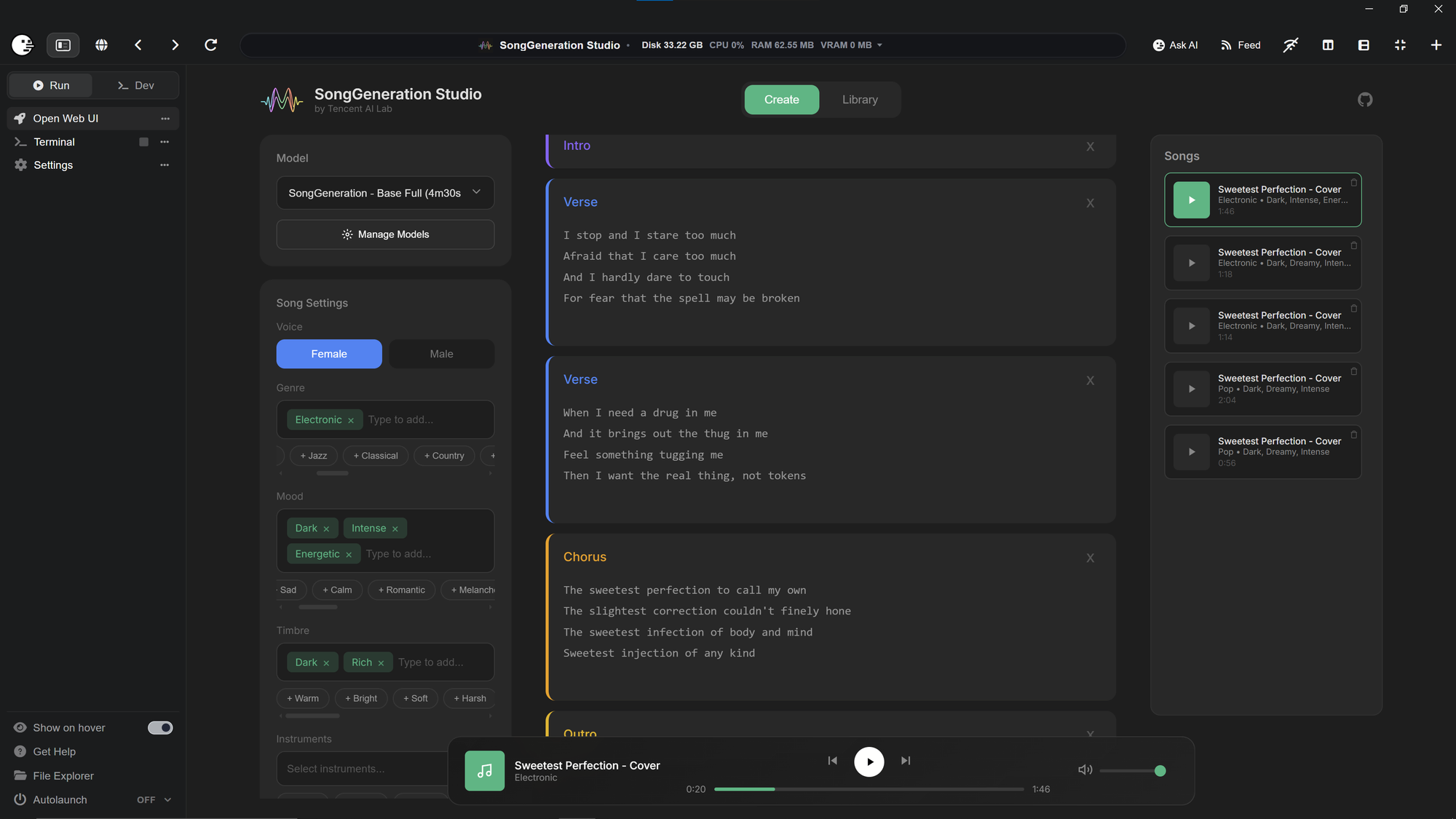
SongGeneration Studio@morpheus•2d agoSonggeneration - FixedYou may have noticed that all Pinokio installer of SongGeneration-Studio and SongGeneration stopped working. ...
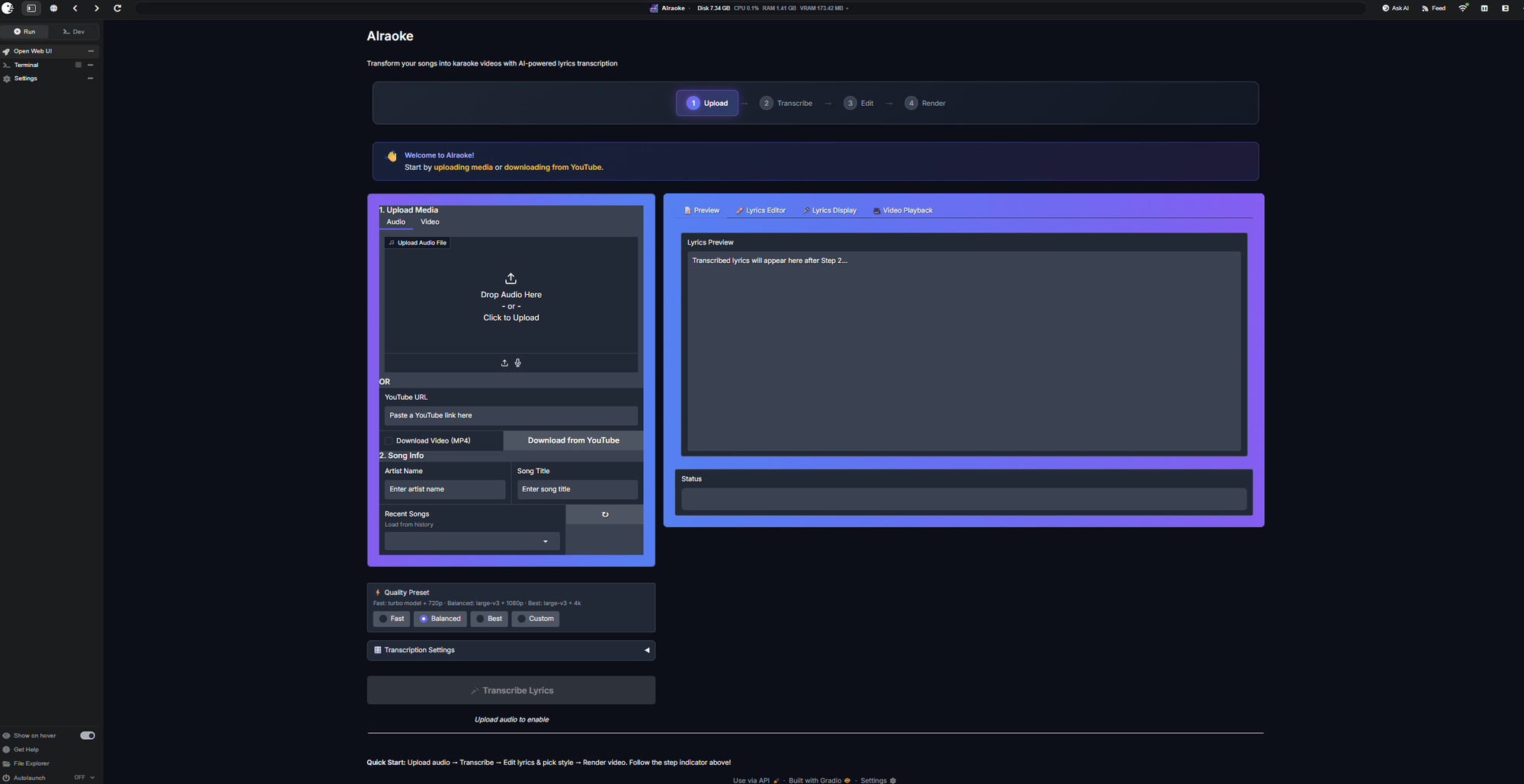
AIraoke@theawakenone•2d agoAIraoke just got a glow-up 🎤Just pushed an update to AIraoke-Pinokio. - Guided workflow, quality presets - YouTube download support - Cus...