
Over the past several updates, I’ve been working through community reports and taking a closer look at how TT...
Launcher updates
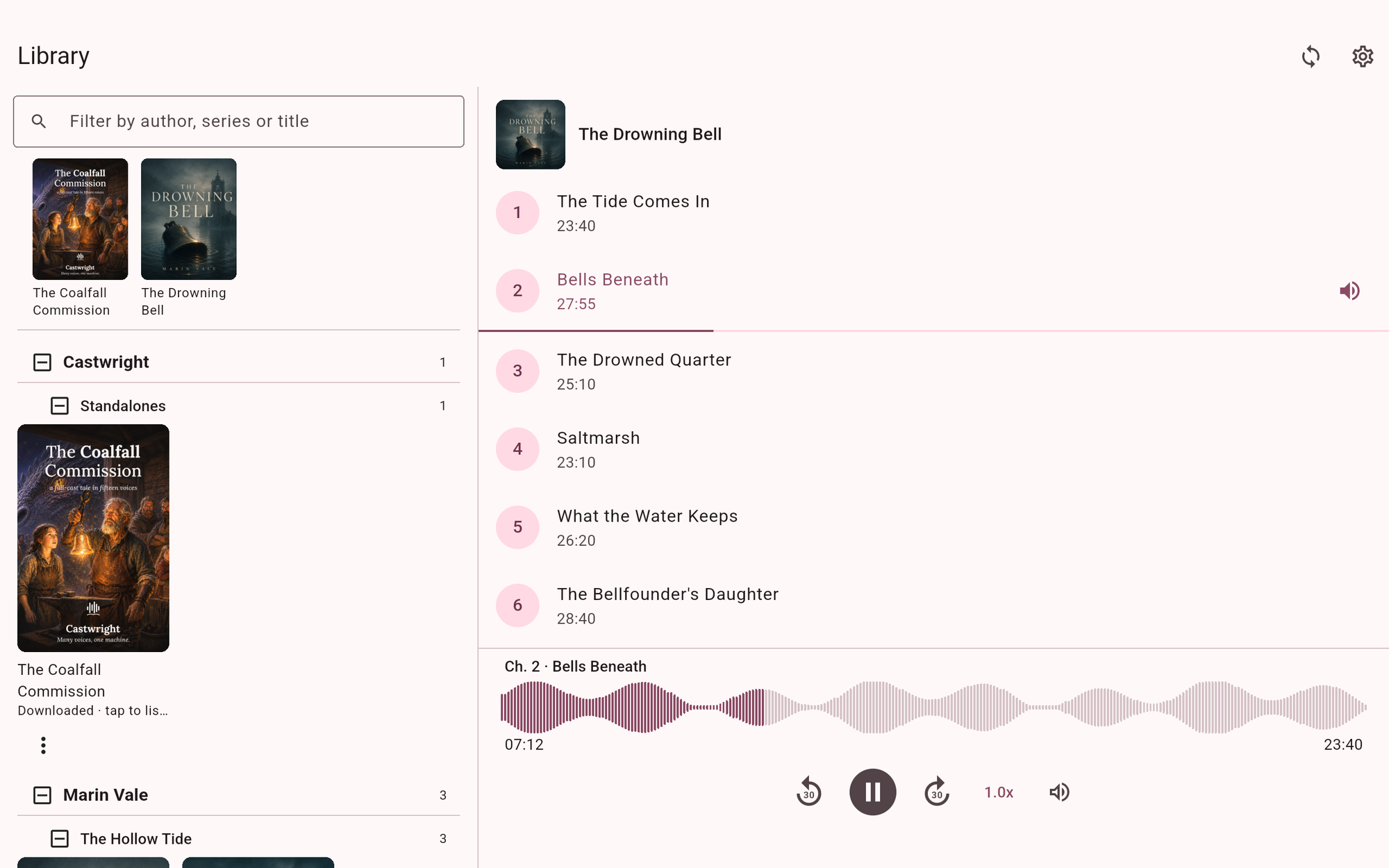
Castwright v1.14.0 — Chinese and Japanese join the cast, and the app grows up on tablets
Quick recap for anyone new: Castwright turns a book into a full-cast audiobook — every character in its own v...
ComfyUI Installer v1.2 — Multiple Instances, GPU Selection and Improved Restarts

🚀 ComfyUI Installer v1.2 — Multiple Instances, GPU Selection and Improved Restarts The Inteliweb AI ComfyUI ...

Remix mode: drop your trained face into ANY scene - 100% on your Mac

Phosphene's new Remix mode fuses two things into a single local render: 1) a Character you trained - a LoRA o...
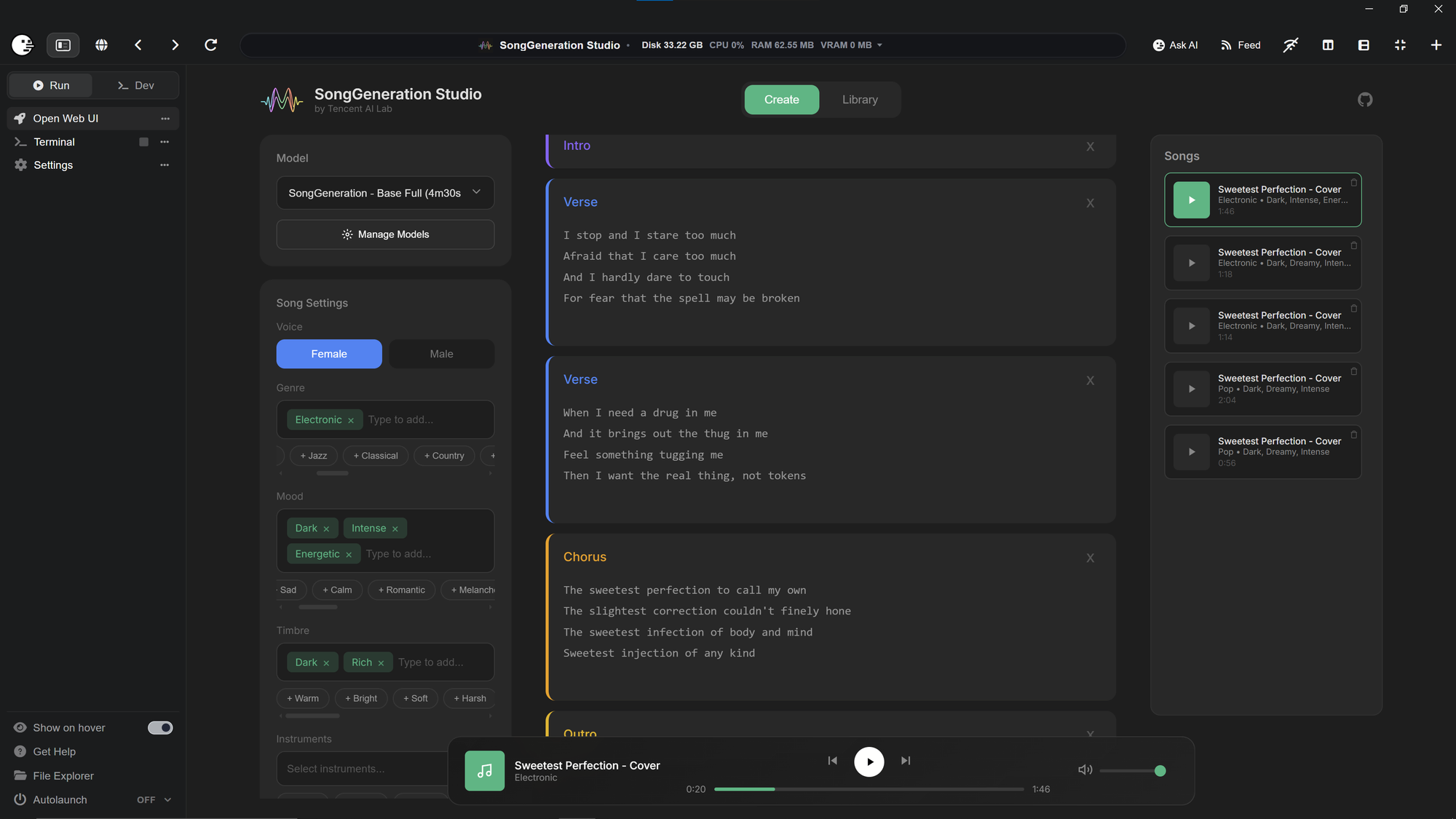
Songgeneration - Fixed

You may have noticed that all Pinokio installer of SongGeneration-Studio and SongGeneration stopped working. ...
Store
#ai186#tts55#image-generation44#video-generation37#utility34#126#agent24#faceswap21#video21#3d19#music19#audio18#image-edit18#audio-generation15#ui15#voice13#voice-clone13#3dgen12#llm12#agents11#image11#ses-klonlama11#song-generation11#training11#music-generation10#song10#automation9#fubar9#models9#pinokio9
AI-powered visual learning platform
Qwen-Image-Layered: Layered Decomposition for Inherent Editablity
Stable Diffusion web UI
Stable Diffusion web UI
Privacy first, AI meeting assistant with 4x faster Parakeet/Whisper live transcription, speaker diarization, and Ollama summarization built on Rust. 100% local processing. no cloud required. Meetily (Meetly Ai - https://meetily.ai) is the #1 Self-hosted, Open-source Ai meeting note taker for macOS & Windows.
Pinokio System Programming: Make your own custom Pinokio
PersonaLive! : Expressive Portrait Image Animation for Live Streaming
Multilingual Voice Understanding Model
Automatic video cutter for Clips and Shorts / Reels / TikTok with an asynchronous batch pipeline to generate vertical and horizontal videos without manual editing.
An open-source, modern-design ChatGPT/LLMs UI/Framework. Supports speech-synthesis, multi-modal, and extensible (function call) plugin system. https://github.com/lobehub/lobe-chat
Openvoice2Featured
Openvoice 2 Web UI - A local web UI for Openvoice2, a multilingual voice cloning TTS https://x.com/myshell_ai/status/1783161876052066793
Extract any sound with text prompts. Memory-optimized SAM-Audio with modern UI.
Contribute to pinokiocomputer/gepeto development by creating an account on GitHub.
A Web UI for easy subtitle using whisper model.
Official implementation of YingMusic-SVC.
A Gradio app with Rerun visualization for Microsoft's TRELLIS.2-4B model that generates textured 3D assets (GLB) from text or images using a two-stage pipeline: text-to-image (Z-Image-Turbo) then image-to-3D (TRELLIS.2).
Automapper for Beat Saber songs, using Python, Machine Learning and hundreds of user-created maps from the past years.
Official code for "F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching"

🦙 Create custom Ollama models with your own system prompts and parameters. Easy-to-use Gradio interface for building personalized AI models with temperature control and custom instructions.