
Over the past several updates, I’ve been working through community reports and taking a closer look at how TT...
Launcher updates
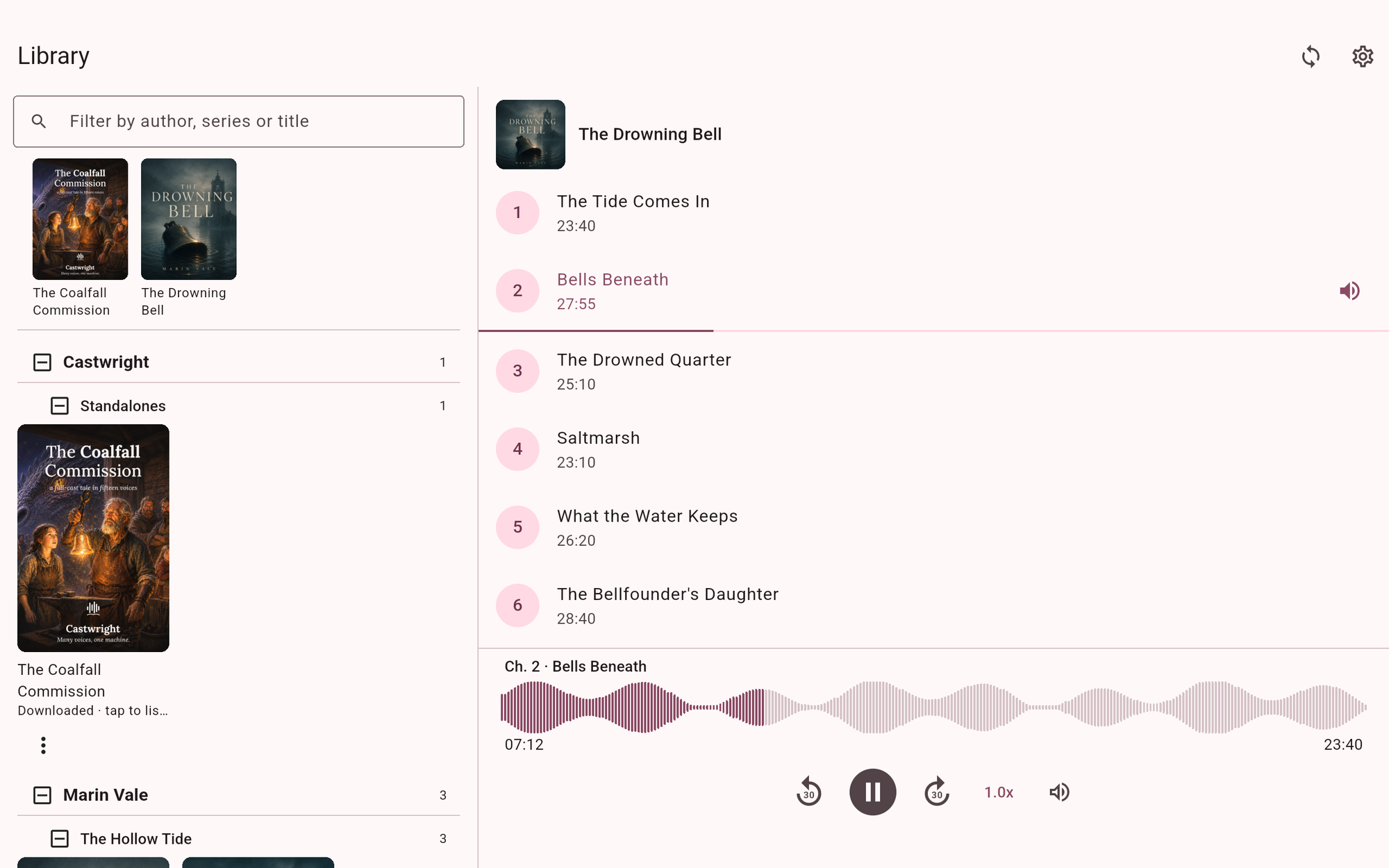
Castwright v1.14.0 — Chinese and Japanese join the cast, and the app grows up on tablets
Quick recap for anyone new: Castwright turns a book into a full-cast audiobook — every character in its own v...
ComfyUI Installer v1.2 — Multiple Instances, GPU Selection and Improved Restarts

🚀 ComfyUI Installer v1.2 — Multiple Instances, GPU Selection and Improved Restarts The Inteliweb AI ComfyUI ...

Remix mode: drop your trained face into ANY scene - 100% on your Mac

Phosphene's new Remix mode fuses two things into a single local render: 1) a Character you trained - a LoRA o...
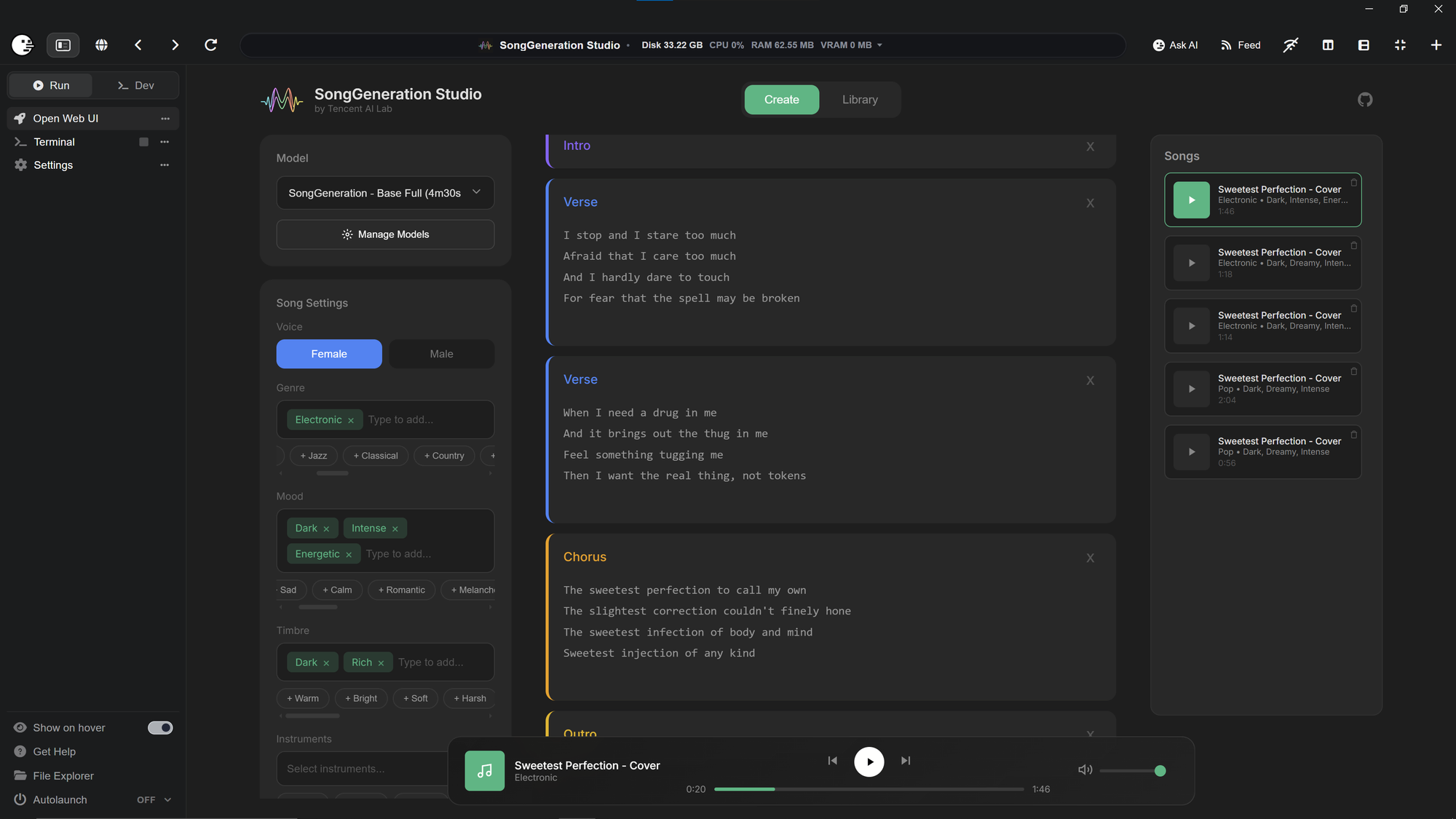
Songgeneration - Fixed

You may have noticed that all Pinokio installer of SongGeneration-Studio and SongGeneration stopped working. ...
Store
Installer for Pinokio on Immutable Linux systems (Steam Deck, Bazzite...) that creates a declarative nix environment within a user account using home-manager, flakes, and nix-user-chroot.

Interpolate, Upscale, Decompress, and Denoise videos easily on Linux/Windows/MacOS.
YuEFeatured
[NVIDIA ONLY] YuEGP--A Web UI for YuE, an Open Full-song Generation Foundation Model (10G VRAM required), via https://github.com/deepbeepmeep/YuEGP
[ICLR 2026] UniVideo: Unified Understanding, Generation, and Editing for Videos
A TTS model capable of generating ultra-realistic dialogue in one pass.
FinGPT: Open-Source Financial Large Language Models! Revolutionize 🔥 We release the trained model on HuggingFace.
Create full comics with AI in seconds
⏰ 60s API 免费接口。每天 60 秒看世界、冬奥会奖牌榜 🏅、小红书/B站/微博/抖音/知乎热搜、金价、油价、天气、翻译、壁纸、Epic 游戏、二维码、猫眼票房|一系列 高质量、开源、可靠、全球 CDN 加速 的开放 API 集合,支持 Docker / Deno / Bun / Cloudflare Workers / Node.js 部署
The AI that actually does things https://openclaw.ai
A Modular AI Image Generation Web-User-Interface, with an emphasis on making powertools easily accessible, high performance, and extensibility. Supports Stable Diffusion, Flux, etc. AI image models, with plans to support AI video, audio, and more in the future.

We’re on a journey to advance and democratize artificial intelligence through open source and open science.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Dataset Helper program to automatically select, re scale and tag Datasets (composed of image and text) for Machine Learning training.
Breakthrough Method for Agile Ai Driven Development
The open-source CapCut alternative
The open-source voice synthesis studio powered by Qwen3-TTS.
Flask-based web UI for AI image/video generation, chat, and text-to-speech with queue management and multi-theme system
A Unified Visual Generator with Interleaved OmniModal Context
The ultimate space for work and life — to find, build, and collaborate with agent teammates that grow with you. We are taking agent harness to the next level — enabling multi-agent collaboration, effortless agent team design, and introducing agents as the unit of work interaction.
Cuda mesh utils.