
Over the past several updates, I’ve been working through community reports and taking a closer look at how TT...
Launcher updates
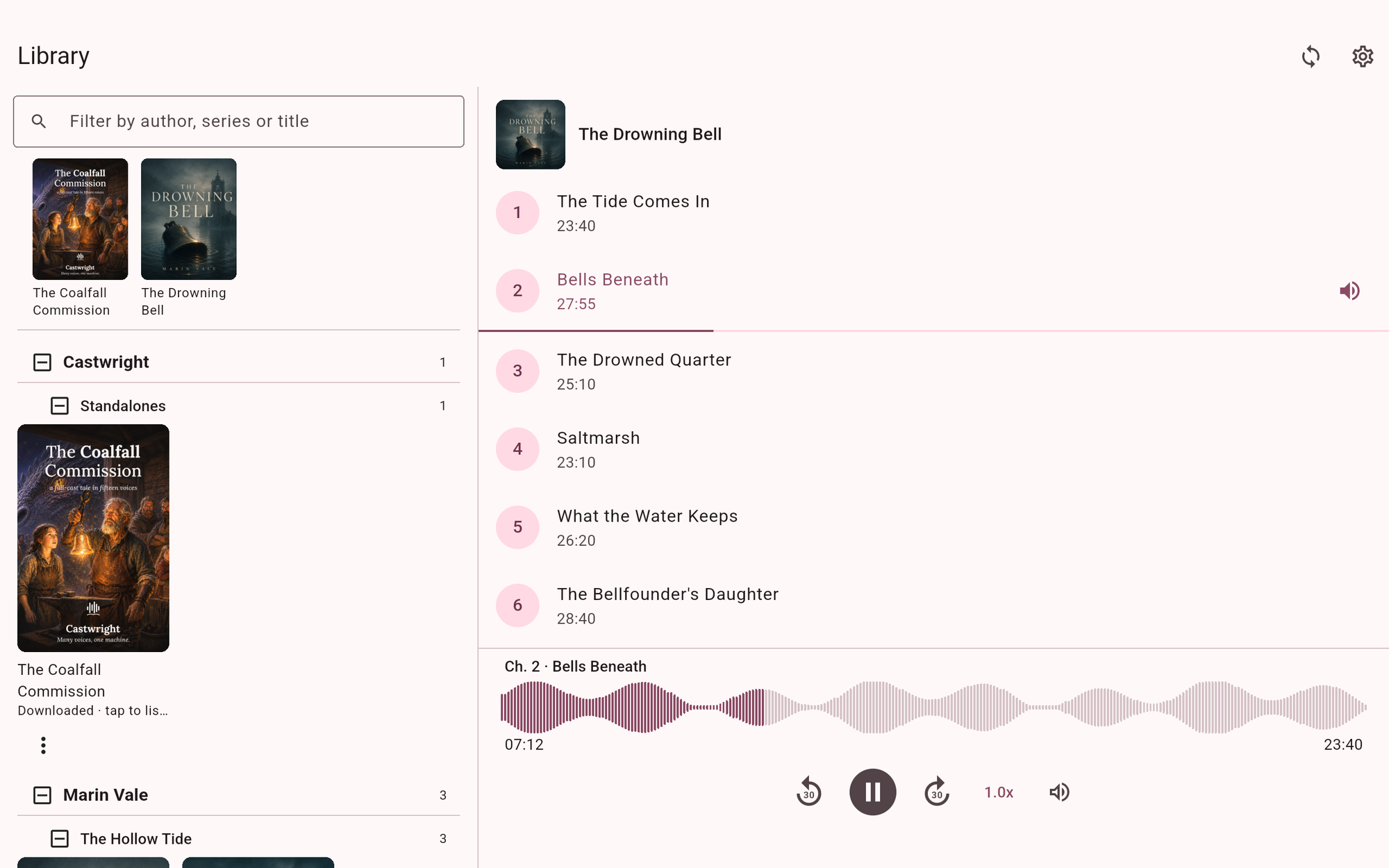
Castwright v1.14.0 — Chinese and Japanese join the cast, and the app grows up on tablets
Quick recap for anyone new: Castwright turns a book into a full-cast audiobook — every character in its own v...
ComfyUI Installer v1.2 — Multiple Instances, GPU Selection and Improved Restarts

🚀 ComfyUI Installer v1.2 — Multiple Instances, GPU Selection and Improved Restarts The Inteliweb AI ComfyUI ...

Remix mode: drop your trained face into ANY scene - 100% on your Mac

Phosphene's new Remix mode fuses two things into a single local render: 1) a Character you trained - a LoRA o...
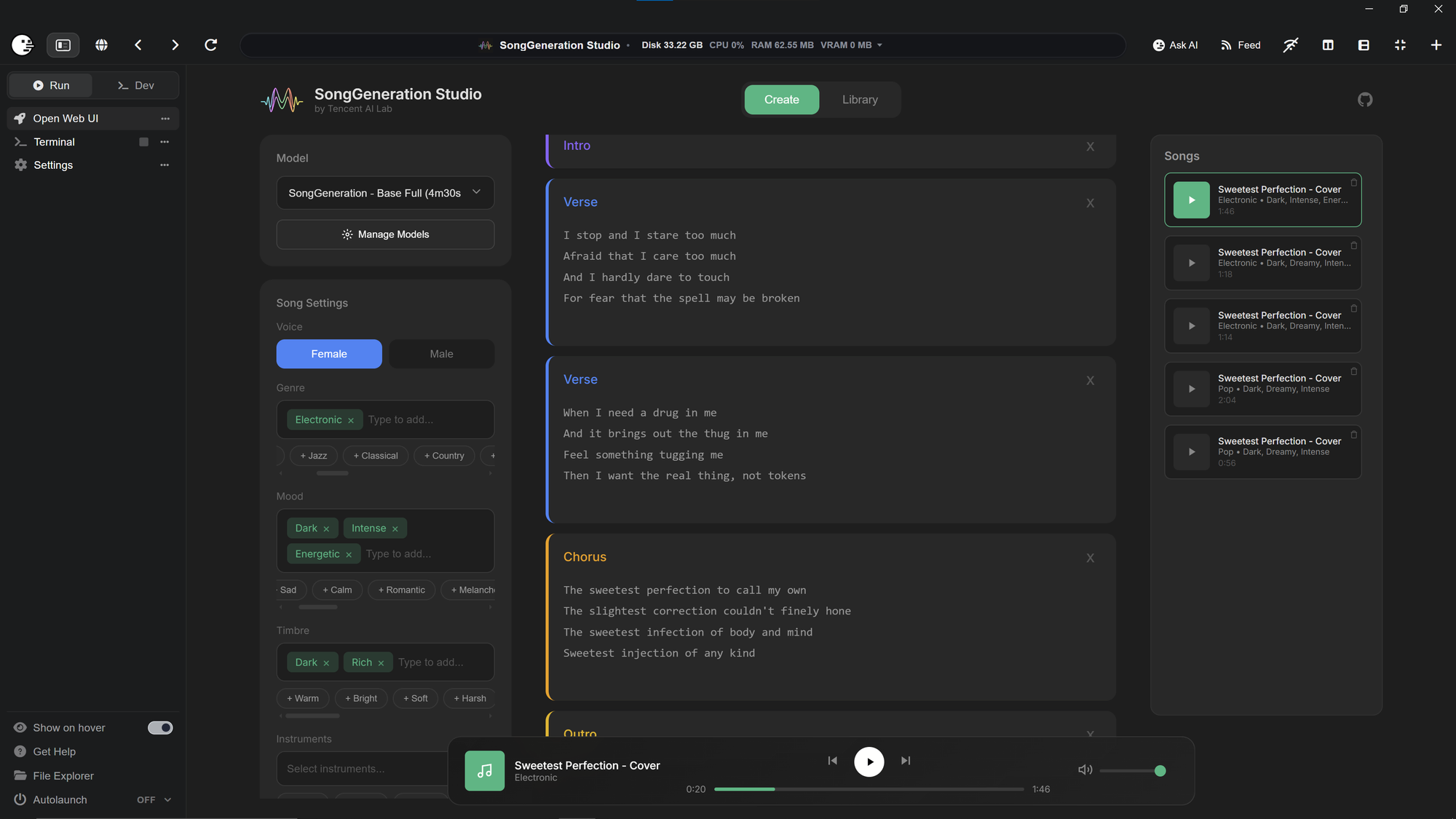
Songgeneration - Fixed

You may have noticed that all Pinokio installer of SongGeneration-Studio and SongGeneration stopped working. ...
Store
Caption images using local LLMs via LM Studio's API. Supports drag & drop datasets and batch processing.

We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Contribute to visualbruno/CuMesh development by creating an account on GitHub.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
首家工业级全流程 AI 影视生产平台。Industry-first professional AI Agent platform for controllable film & video production. From shorts to live-action with Hollywood-standard workflows.
Stable Diffusion web UI UX
Pinokio wrapper for MilimoVideo with automatic VRAM-aware low-VRAM backend mode.

Real-time Vision Language Model interaction via webcam - WebRTC-based web interface
📨 The ultimate social media scheduling tool, with a bunch of AI 🤖
scrape data data from Google Maps. Extracts data such as the name, address, phone number, website URL, rating, reviews number, latitude and longitude, reviews,email and more for each place
The open source coding agent.
The best local UI for large language models, with easy setup and powerful features. 100% offline.
Crea documentos de estructura de marca corporativa mediante entrevista guiada con IA
An open-source AI agent that brings the power of Gemini directly into your terminal.
AI Song Generation with Full Style Control - Generate complete songs with lyrics, vocals, and instrumental tracks using Tencent AI Lab's SongGeneration (LeVo) model. [NVIDIA ONLY]

Chatbot local con llama.cpp — sin internet, sin telemetría, 100% privado
AI-powered video production pipeline — topic to finished video, fully automated
InstantMesh: Efficient 3D Mesh Generation from a Single Image with Sparse-view Large Reconstruction Models
We’re on a journey to advance and democratize artificial intelligence through open source and open science.