
Over the past several updates, I’ve been working through community reports and taking a closer look at how TT...
Launcher updates
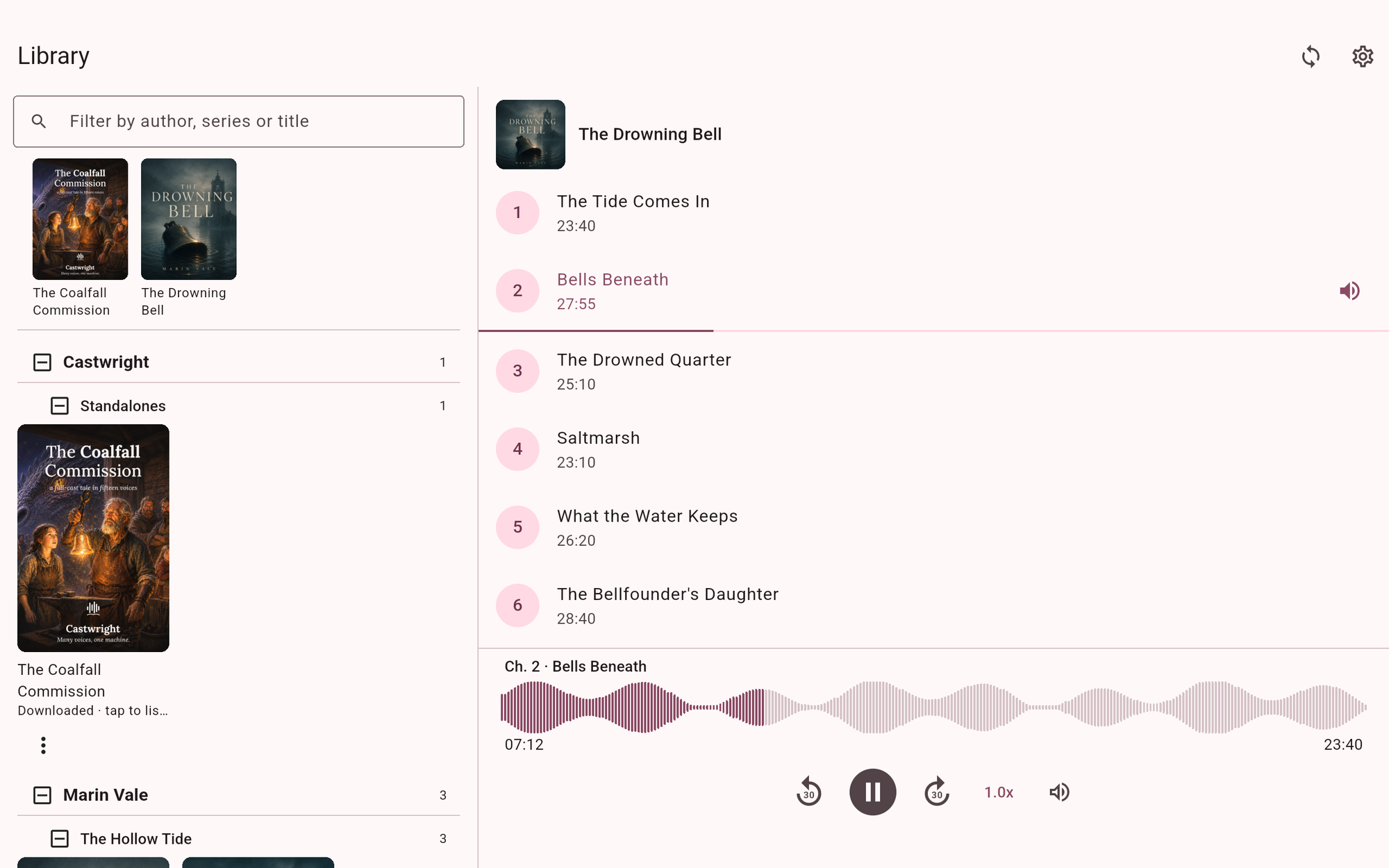
Castwright v1.14.0 — Chinese and Japanese join the cast, and the app grows up on tablets
Quick recap for anyone new: Castwright turns a book into a full-cast audiobook — every character in its own v...
ComfyUI Installer v1.2 — Multiple Instances, GPU Selection and Improved Restarts

🚀 ComfyUI Installer v1.2 — Multiple Instances, GPU Selection and Improved Restarts The Inteliweb AI ComfyUI ...

Remix mode: drop your trained face into ANY scene - 100% on your Mac

Phosphene's new Remix mode fuses two things into a single local render: 1) a Character you trained - a LoRA o...
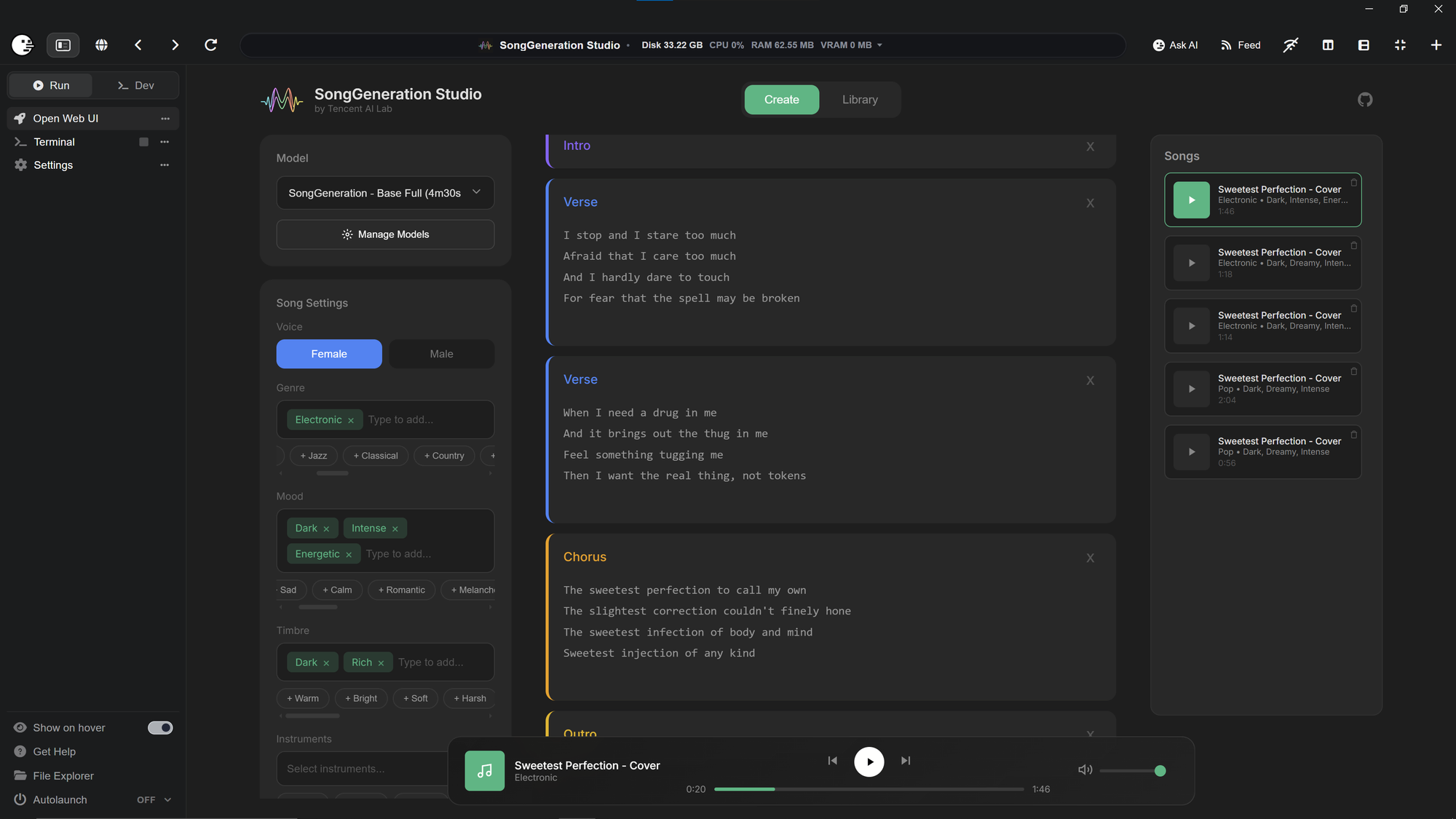
Songgeneration - Fixed

You may have noticed that all Pinokio installer of SongGeneration-Studio and SongGeneration stopped working. ...
Store
Open Source Speech Language Model
LTX-Desktop powered By WanGP itself powered among other things by LTX-2 Engine
precompiled Cuda kernels
Stock Scanner with Local LLM for Sentiment Analysis - McMaster Engineering Capstone 2025. Real-time stock market scanner with AI-driven sentiment analysis using a local LLM. Analyze news, social media for trading insights. Custom technical indicators, privacy-focused, user-friendly. Ideal for investors, traders, developers in AI finance.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Run Open Notebook locally via Docker with one-click install, start, and shutdown.

Unified Efficient Fine-Tuning of 100+ LLMs & VLMs (ACL 2024)
Create your own AI comic with a single prompt
The official code repository for LeVo: High-Quality Song Generation with Multi-Preference Alignment
Official inference framework for 1-bit LLMs
PhotoMakerFeatured
Customizing Realistic Human Photos via Stacked ID Embedding https://github.com/TencentARC/PhotoMaker

AITownFeatured
Build and customize your own version of AI town - a virtual town where AI characters live, chat and socialize https://github.com/a16z-infra/ai-town

PCMFeatured
Phased Consistency Model - generate high quality images with 2 steps https://huggingface.co/spaces/radames/Phased-Consistency-Model-PCM
flashdiffusionFeatured
Accelerating any conditional diffusion model for few steps image generation https://gojasper.github.io/flash-diffusion-project/

Build AI Agents, Visually
F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching https://huggingface.co/spaces/mrfakename/E2-F5-TTS
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Multi-Platform Package Manager for Stable Diffusion
An AI Hedge Fund Team