
Over the past several updates, I’ve been working through community reports and taking a closer look at how TT...
Launcher updates
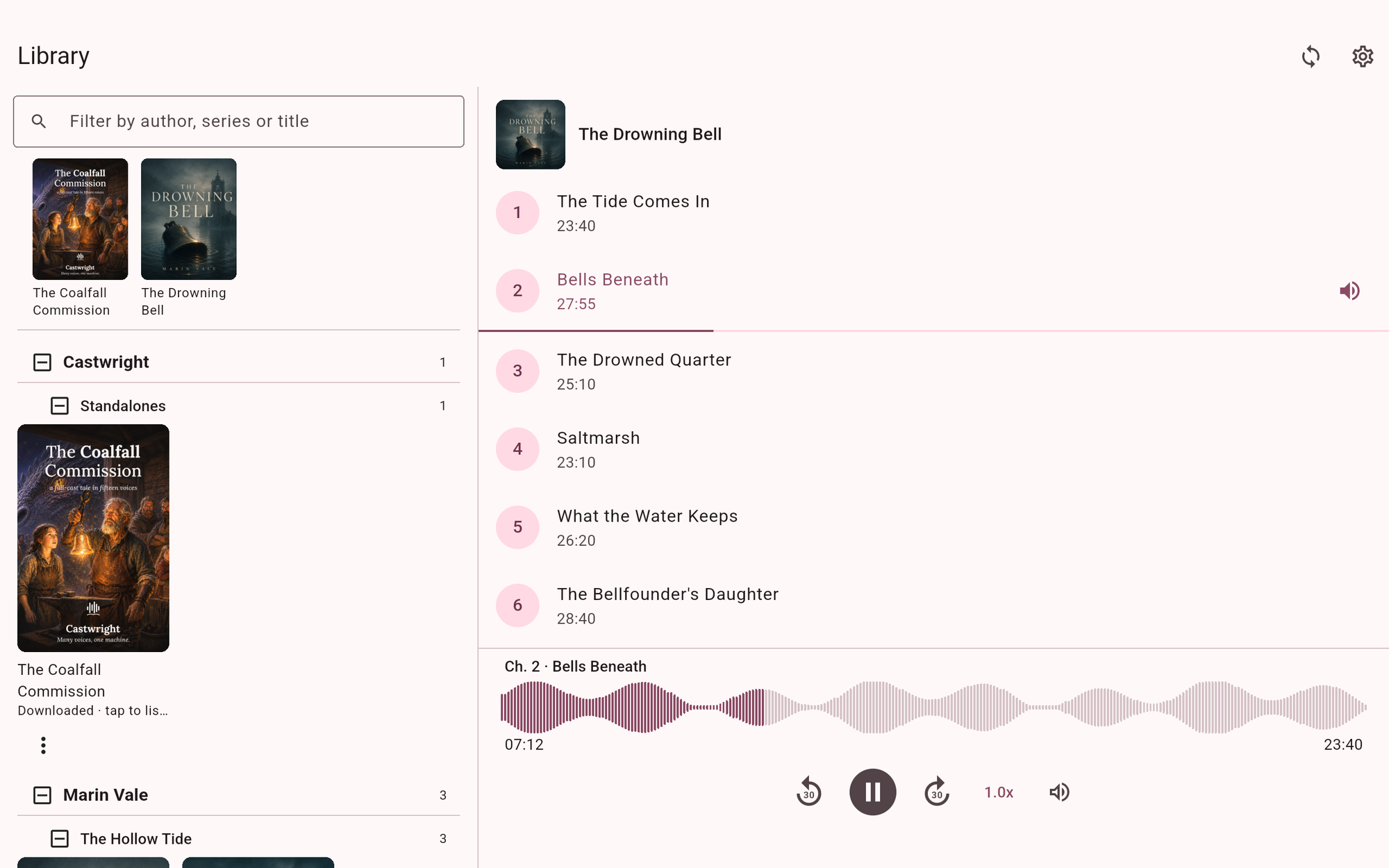
Castwright v1.14.0 — Chinese and Japanese join the cast, and the app grows up on tablets
Quick recap for anyone new: Castwright turns a book into a full-cast audiobook — every character in its own v...
ComfyUI Installer v1.2 — Multiple Instances, GPU Selection and Improved Restarts

🚀 ComfyUI Installer v1.2 — Multiple Instances, GPU Selection and Improved Restarts The Inteliweb AI ComfyUI ...

Remix mode: drop your trained face into ANY scene - 100% on your Mac

Phosphene's new Remix mode fuses two things into a single local render: 1) a Character you trained - a LoRA o...
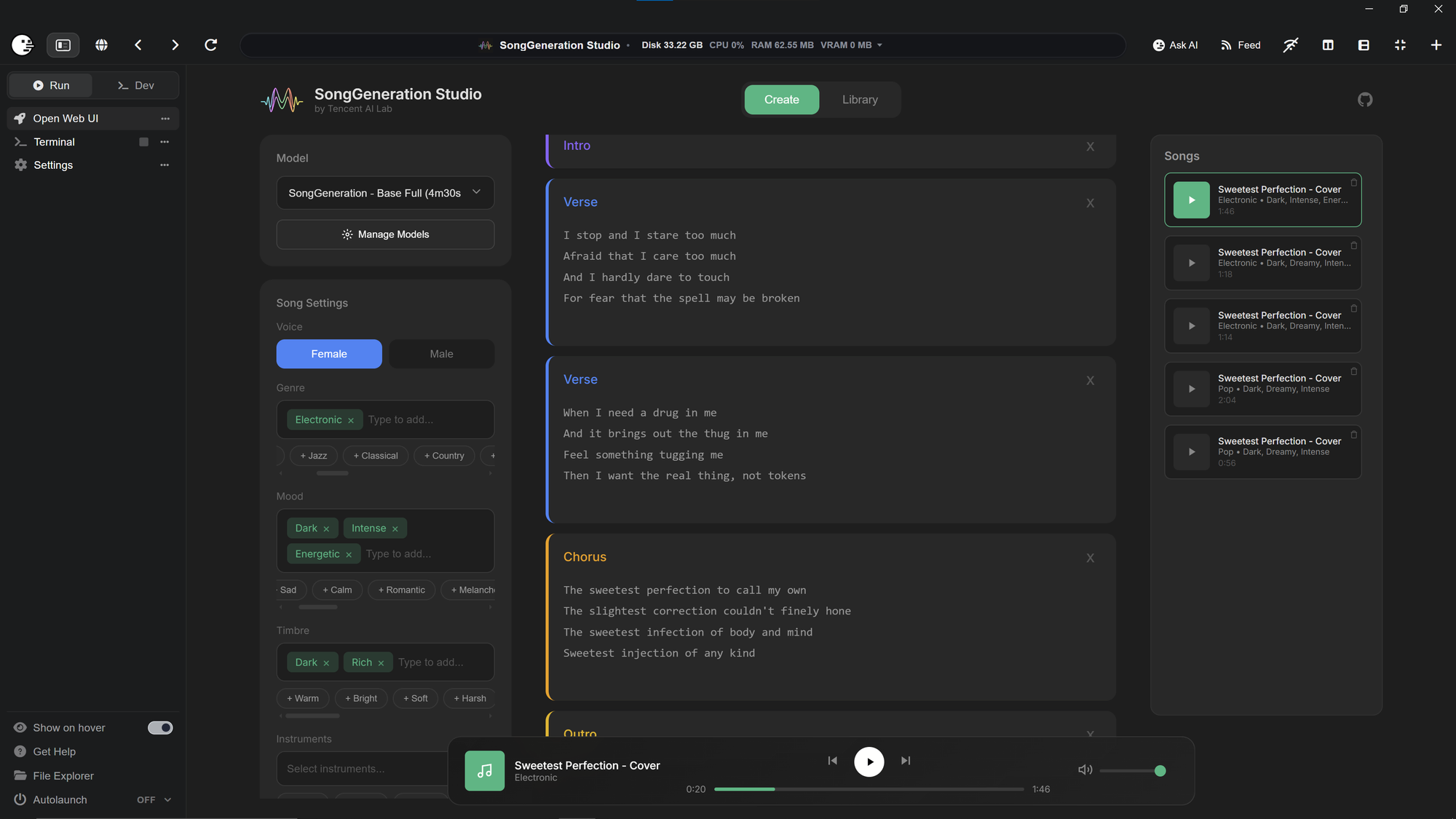
Songgeneration - Fixed

You may have noticed that all Pinokio installer of SongGeneration-Studio and SongGeneration stopped working. ...
Store
FastMovieAI 是一个功能完整的开源短剧/短视频创作平台,采用前后端分离架构,提供 AI 驱动的视频内容创作能力。平台集成了用户管理、支付系统、内容管理、视频生成等完整功能模块,适合内容创作者和视频制作团队使用。
A complete browser-based reverse engineering platform built on Rizin, running entirely client-side via WebAssembly.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
NSFW-Uncensored-video
MAX ~60sec Video - AI Limits
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Forge for stable-diffusion-webui-amdgpu (formerly stable-diffusion-webui-directml)
Use OCR in Windows quickly and easily with Text Grab. With optional background process and notifications.
Fast 4 step inference with Qwen Image Edit 2509
DreamID-V: Bridging the Image-to-Video Gap for High-Fidelity Face Swapping via Diffusion Transformer
Restore videos with pixelated/mosaic regions
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
A simple, high-quality voice conversion tool focused on ease of use and performance.
real time face swap and one-click video face swap with only a single image. You can use one face or ten faces to replace in realtime using insightface, mouth mask, face tracking
Contribute to yoheinakajima/babyagi development by creating an account on GitHub.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
real time face swap and one-click video deepfake with only a single image