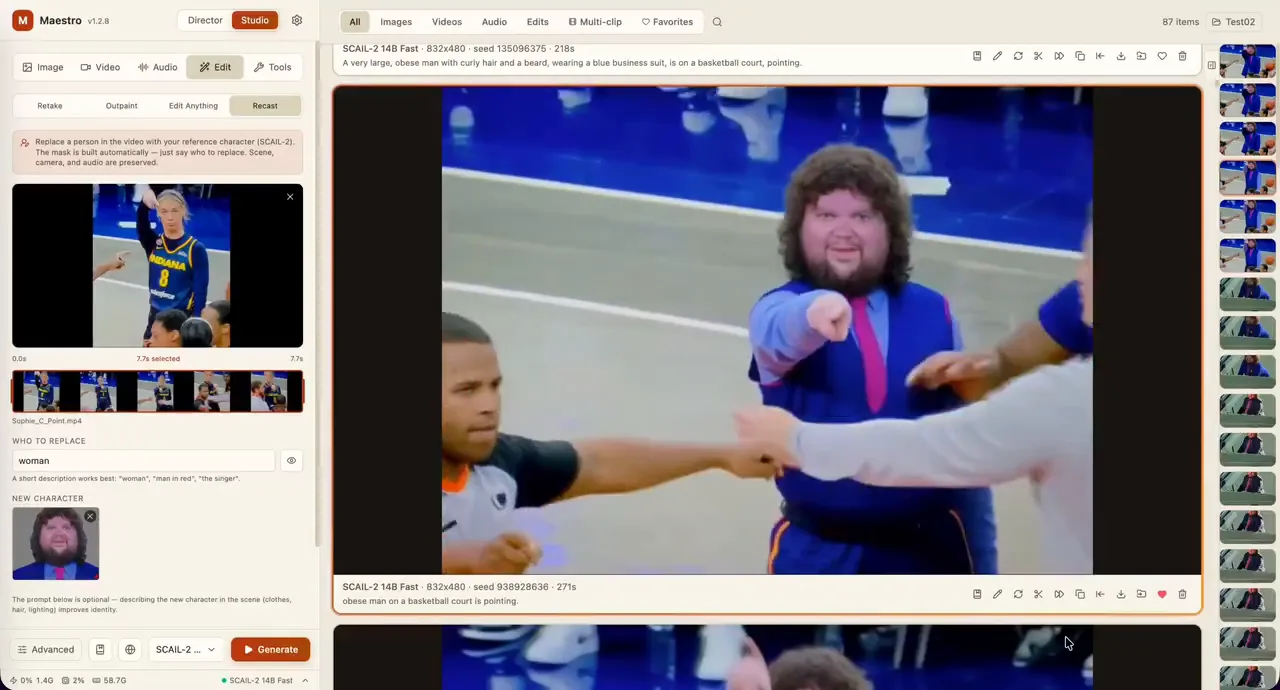
An all-in-one, 100% local AI video, image & music studio. Its Director mode turns a single prompt into a full music video or short film — LLM-planned, shot by shot. Built on the WanGP pipeline (Wan 2.1/2.2, LTX-2.3, Qwen, Hunyuan Video, Flux). Requires an NVIDIA GPU (6GB+ VRAM).
Prompt Orchestrator that turns module-based game design (genre, mechanics, visuals, menus, audio) into a complete, playable HTML5 game generated by your chosen AI provider. Supports OpenAI, Gemini, Claude, Ollama, and LM Studio. Every game ships as a single self-contained HTML file.
a state-of-the-art open-source model for fast feedforward 3D reconstruction from a single image, developed in collaboration between Tripo AI and Stability AI. https://huggingface.co/spaces/stabilityai/TripoSR
AI investigation agent that resolves entities across corporate registries, campaign finance, lobbying, and contract data to surface non-obvious connections. Pre-built desktop app, auto-connected to Ollama.
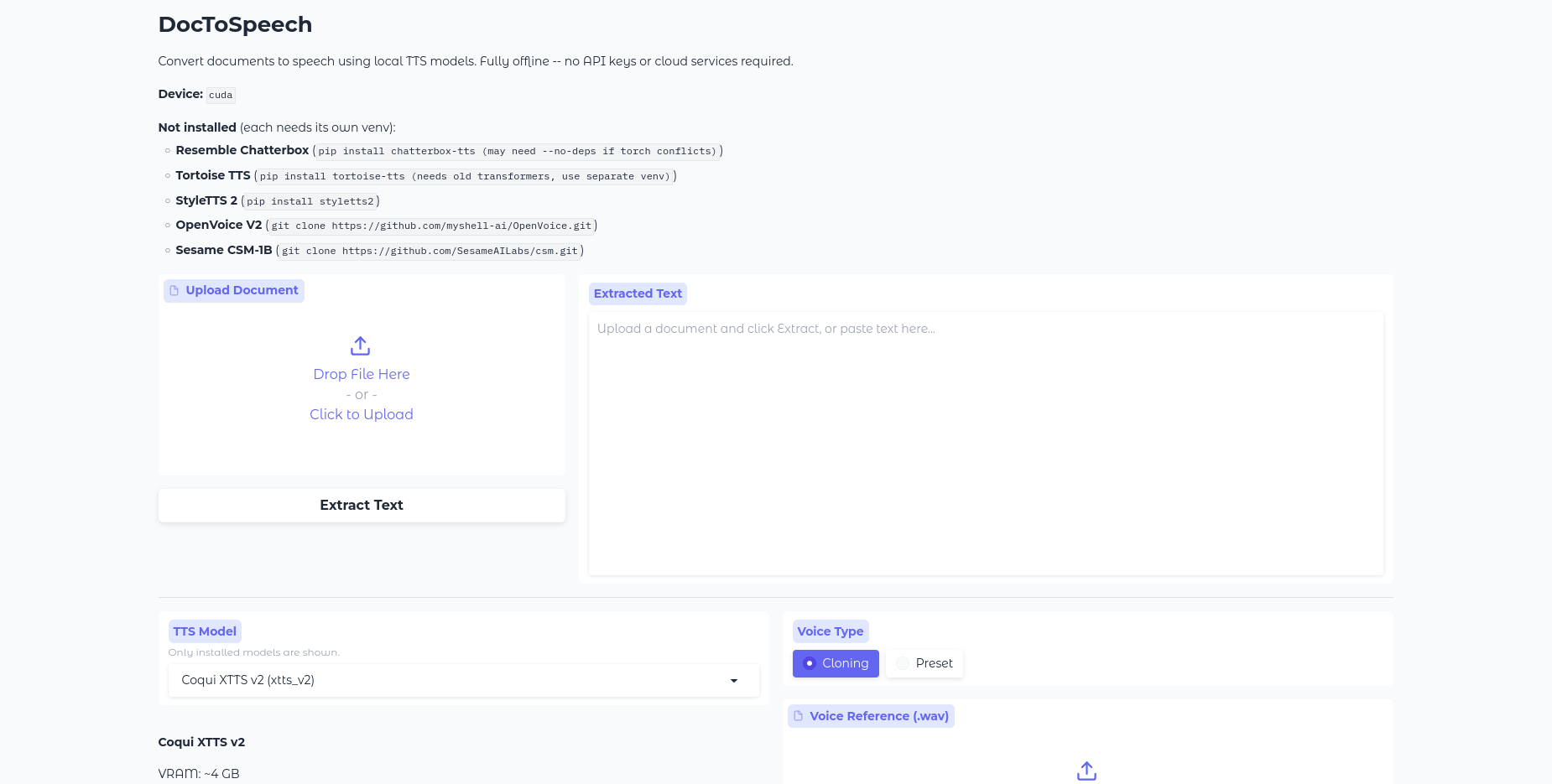
Super Optimized Gradio UI for AI video creation for GPU poor machines (6GB+ VRAM). Supports Wan 2.1/2.2, Qwen, Hunyuan Video, LTX Video and Flux. https://github.com/deepbeepmeep/Wan2GP


 @blizaine
@blizaine

 49 check-ins
49 check-ins @dsrpt
@dsrpt









