
Over the past several updates, I’ve been working through community reports and taking a closer look at how TT...
Launcher updates
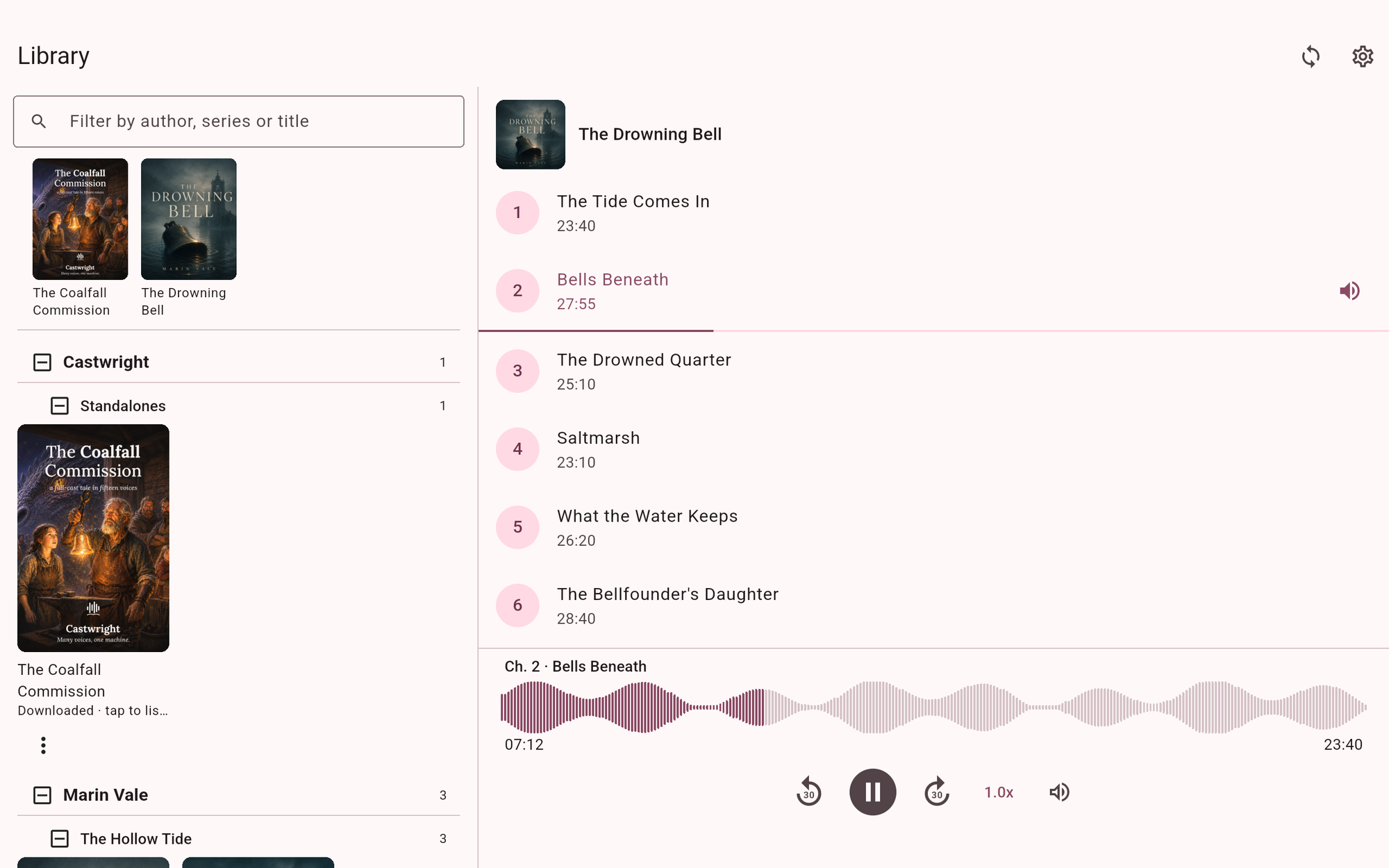
Castwright v1.14.0 — Chinese and Japanese join the cast, and the app grows up on tablets
Quick recap for anyone new: Castwright turns a book into a full-cast audiobook — every character in its own v...
ComfyUI Installer v1.2 — Multiple Instances, GPU Selection and Improved Restarts

🚀 ComfyUI Installer v1.2 — Multiple Instances, GPU Selection and Improved Restarts The Inteliweb AI ComfyUI ...

Remix mode: drop your trained face into ANY scene - 100% on your Mac

Phosphene's new Remix mode fuses two things into a single local render: 1) a Character you trained - a LoRA o...
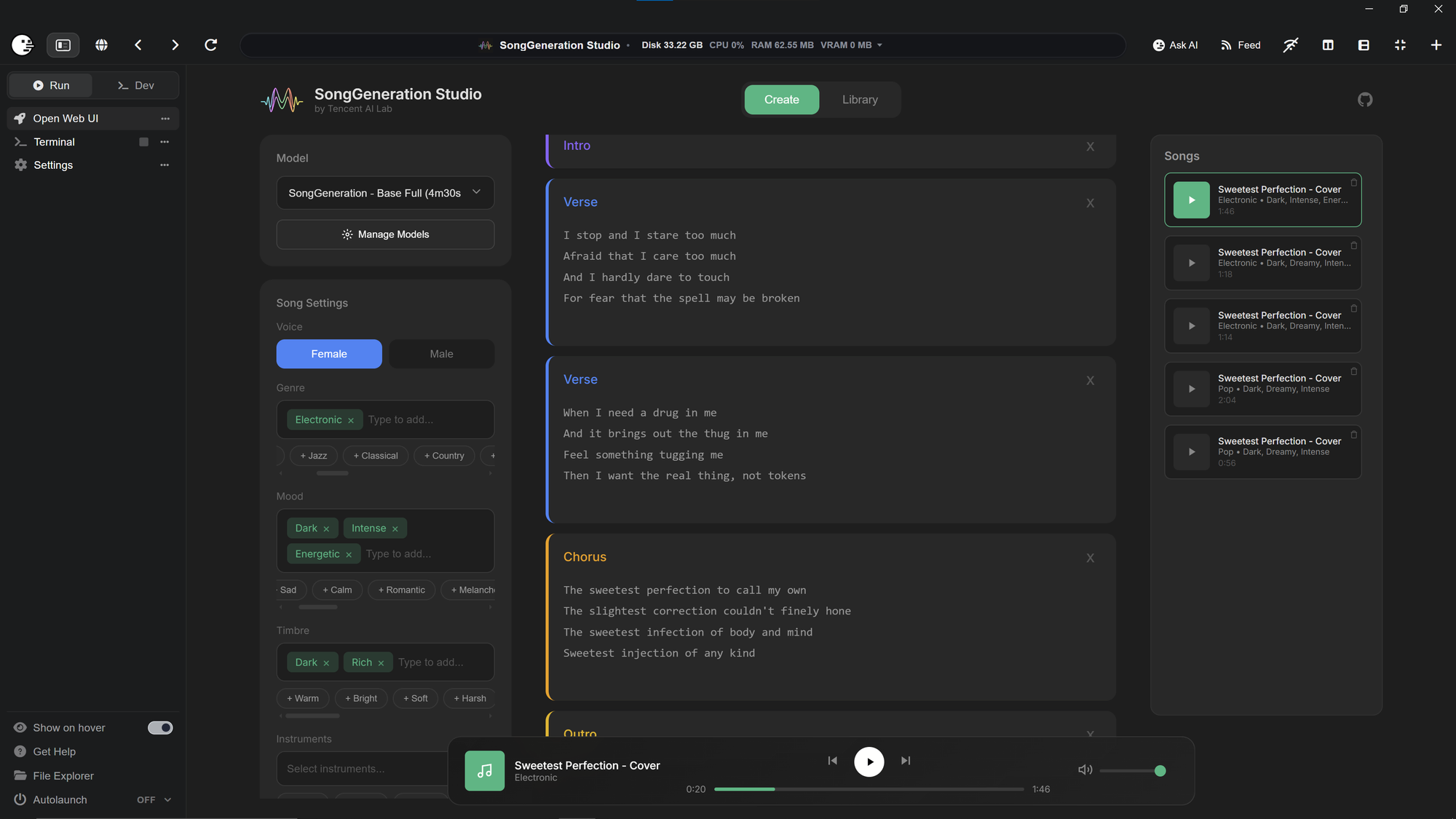
Songgeneration - Fixed

You may have noticed that all Pinokio installer of SongGeneration-Studio and SongGeneration stopped working. ...
Store
#ai186#tts55#image-generation44#video-generation37#utility34#126#agent24#faceswap21#video21#3d19#music19#audio18#image-edit18#audio-generation15#ui15#voice13#voice-clone13#3dgen12#llm12#agents11#image11#ses-klonlama11#song-generation11#training11#music-generation10#song10#automation9#fubar9#models9#pinokio9
No apps found.