
Over the past several updates, I’ve been working through community reports and taking a closer look at how TT...
Launcher updates
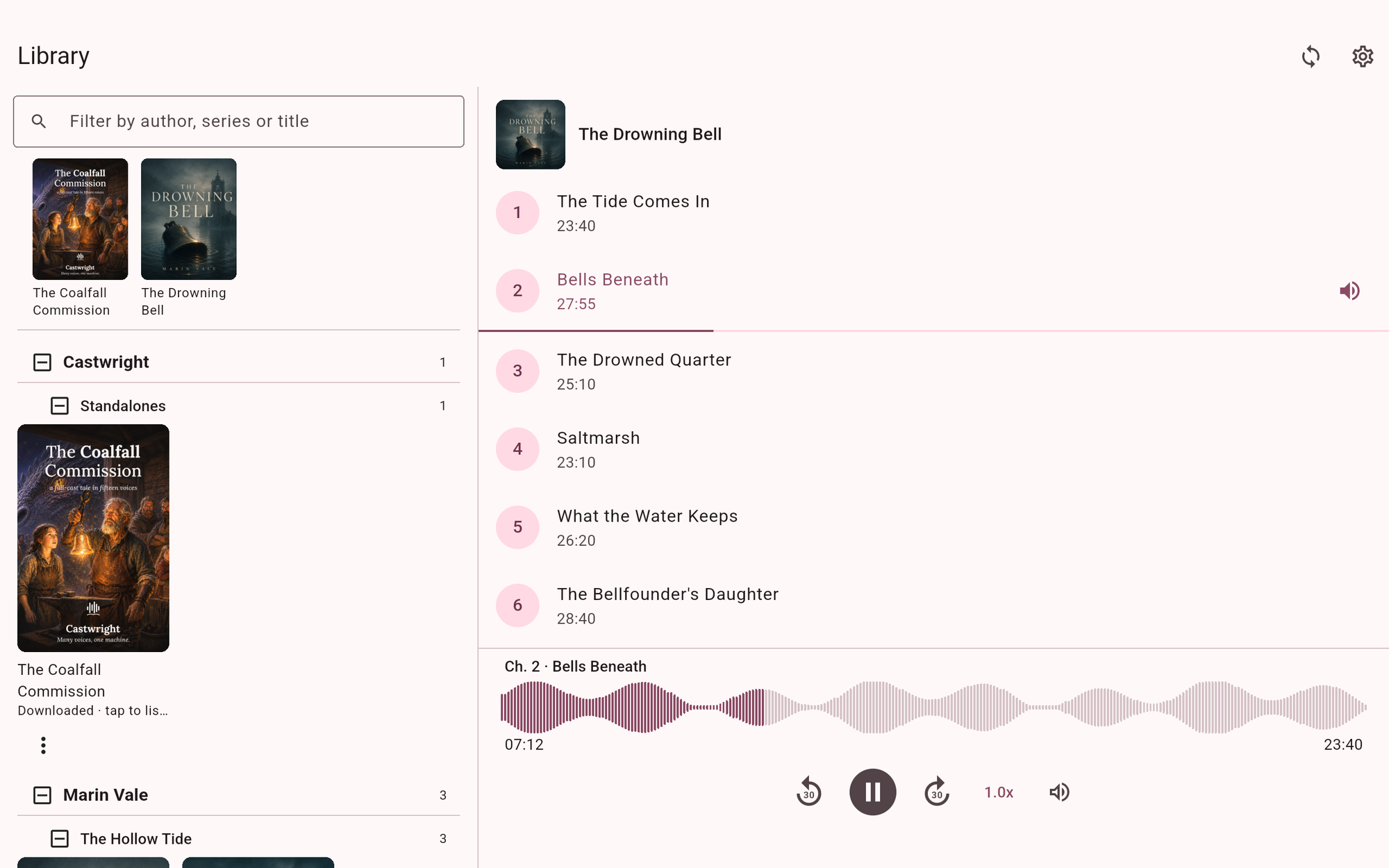
Castwright v1.14.0 — Chinese and Japanese join the cast, and the app grows up on tablets
Quick recap for anyone new: Castwright turns a book into a full-cast audiobook — every character in its own v...
ComfyUI Installer v1.2 — Multiple Instances, GPU Selection and Improved Restarts

🚀 ComfyUI Installer v1.2 — Multiple Instances, GPU Selection and Improved Restarts The Inteliweb AI ComfyUI ...

Remix mode: drop your trained face into ANY scene - 100% on your Mac

Phosphene's new Remix mode fuses two things into a single local render: 1) a Character you trained - a LoRA o...
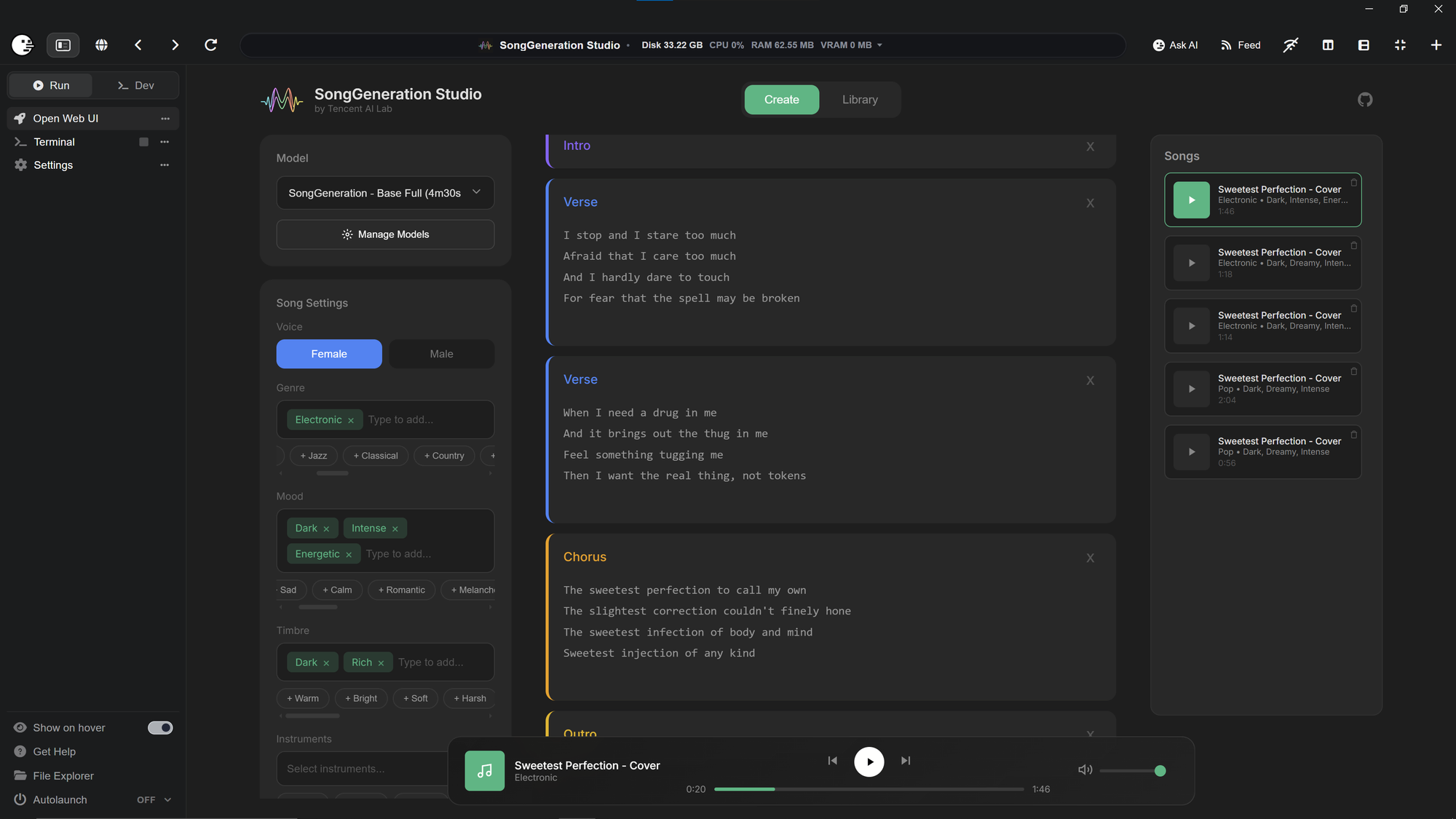
Songgeneration - Fixed

You may have noticed that all Pinokio installer of SongGeneration-Studio and SongGeneration stopped working. ...
Store
Spanish finetune for the original F5 model.
Ultralytics YOLO 🚀
Implementation of PocketXMol, the pocket-interacting molecular generative foundation model.
Optimized for 8Gb inference LTX-2 audio–video generative model. + Web UI. Model created by:
This app converts text into realistic speech voices in 24 European languages. Users can enter text and choose from multiple languages to create audio. It also offers voice cloning functionality, al...
Fully automatic censorship removal for language models
Open-source AI audiobook studio. A free, private alternative to ElevenLabs. 3 voice modes, per-sentence voice & emotion control, LLM smart character analysis, mixed-voice generation. Runs 100% locally on your GPU with zero API costs.
Industry leading face manipulation platform

CADAM is the open source text-to-CAD web application
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
This tool creates videos where a person's lips move in sync with spoken audio, using just a single image and an audio file. Users upload a photo and voice recording, then customize the video length...
FireRed-Image-Edit-1.0
aider is AI pair programming in your terminal
Multi-column chat interface for OpenClaw agents
A Family of Open Sourced Music Foundation Models
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Caption private data with uncensored models