
Over the past several updates, I’ve been working through community reports and taking a closer look at how TT...
Launcher updates
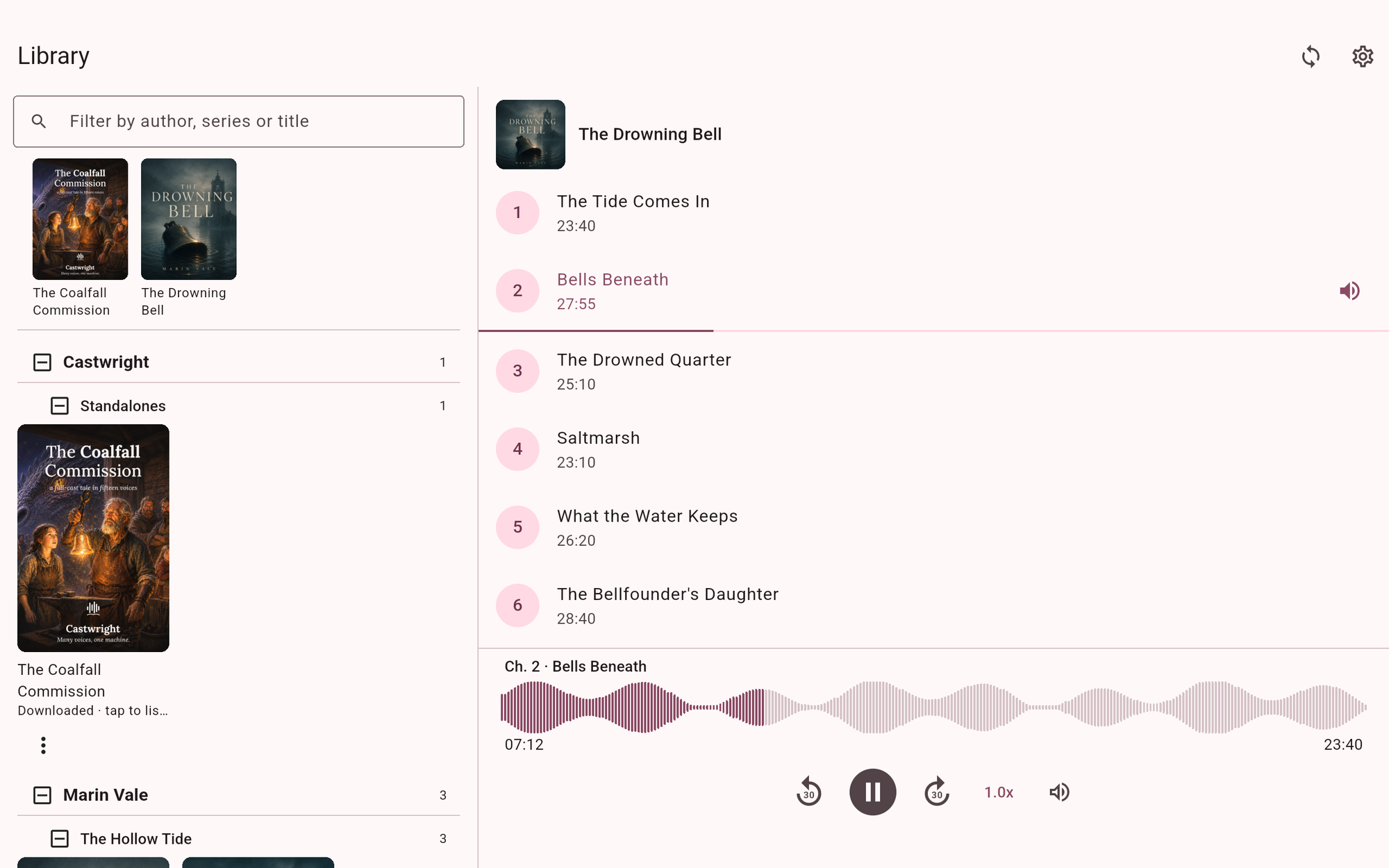
Castwright v1.14.0 — Chinese and Japanese join the cast, and the app grows up on tablets
Quick recap for anyone new: Castwright turns a book into a full-cast audiobook — every character in its own v...
ComfyUI Installer v1.2 — Multiple Instances, GPU Selection and Improved Restarts

🚀 ComfyUI Installer v1.2 — Multiple Instances, GPU Selection and Improved Restarts The Inteliweb AI ComfyUI ...

Remix mode: drop your trained face into ANY scene - 100% on your Mac

Phosphene's new Remix mode fuses two things into a single local render: 1) a Character you trained - a LoRA o...
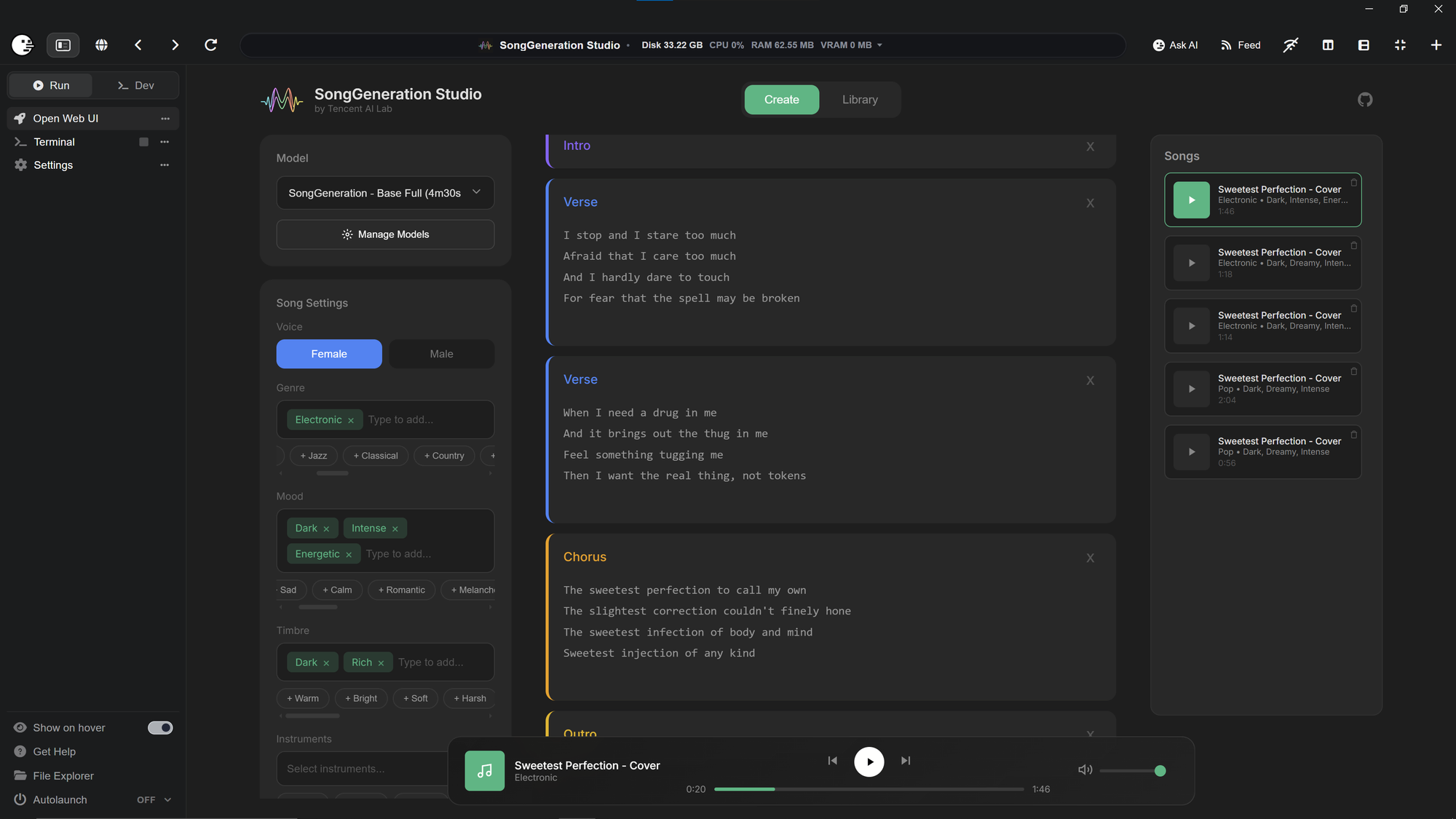
Songgeneration - Fixed

You may have noticed that all Pinokio installer of SongGeneration-Studio and SongGeneration stopped working. ...
Store
[CVPR 2025] MMAudio: Taming Multimodal Joint Training for High-Quality Video-to-Audio Synthesis
An easy 1-click way to create beautiful artwork on your PC using AI, with no tech knowledge. Provides a browser UI for generating images from text prompts and images. Just enter your text prompt, and see the generated image.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Customizing Realistic Human Photos via Stacked ID Embedding with SDXL model switching support. Load any local SDXL .safetensors checkpoint directly from the UI.

Make Discord your LLM frontend - Supports any OpenAI compatible API (Ollama, xAI, Gemini, OpenRouter and more)
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
基於OpenVino-int8權重,精簡的QwenASR小工具,用於即時辨識以及字幕轉換使用
A Gradio-based web UI for voice cloning and voice design, powered by Qwen3-TTS & VibeVoice. Can use Whisper or VibeVoice-ASR for automatic transcription. Improved from the FrankyB origial version
A Gradio-based web UI for voice cloning and voice design, powered by Qwen3-TTS & VibeVoice. Can use Whisper or VibeVoice-ASR for automatic transcription. Improved from the FrankyB origial version
Natively is an open-source, privacy-first AI meeting assistant and the best alternative to Cluely. It supports both local models and cloud AI providers , delivering real-time assistance during meetings, interviews, and conversations while remaining invisible in screen shares and recordings.
High performance self-hosted photo and video management solution.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
A feature-rich command-line audio/video downloader
We’re on a journey to advance and democratize artificial intelligence through open source and open science.