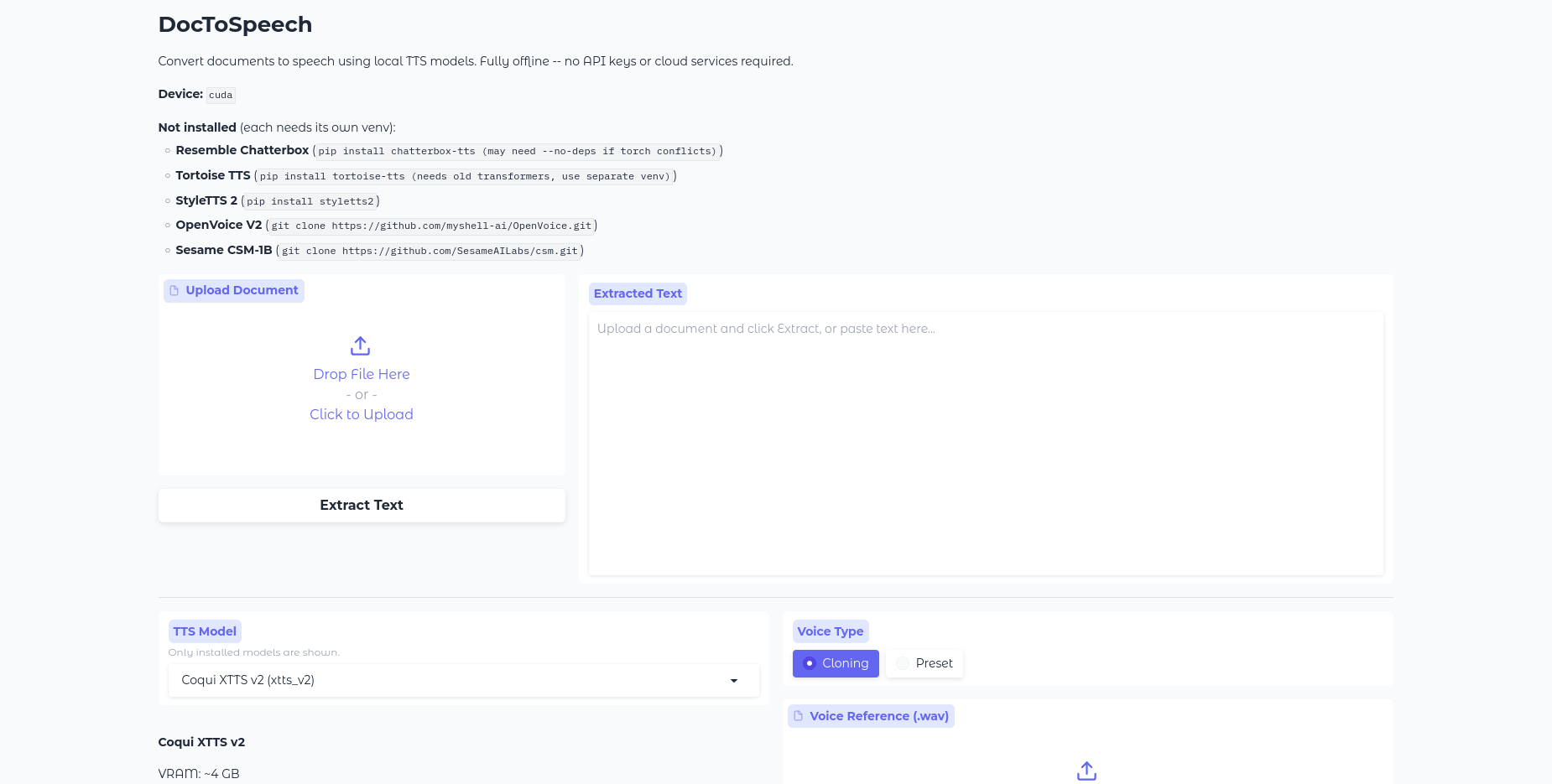
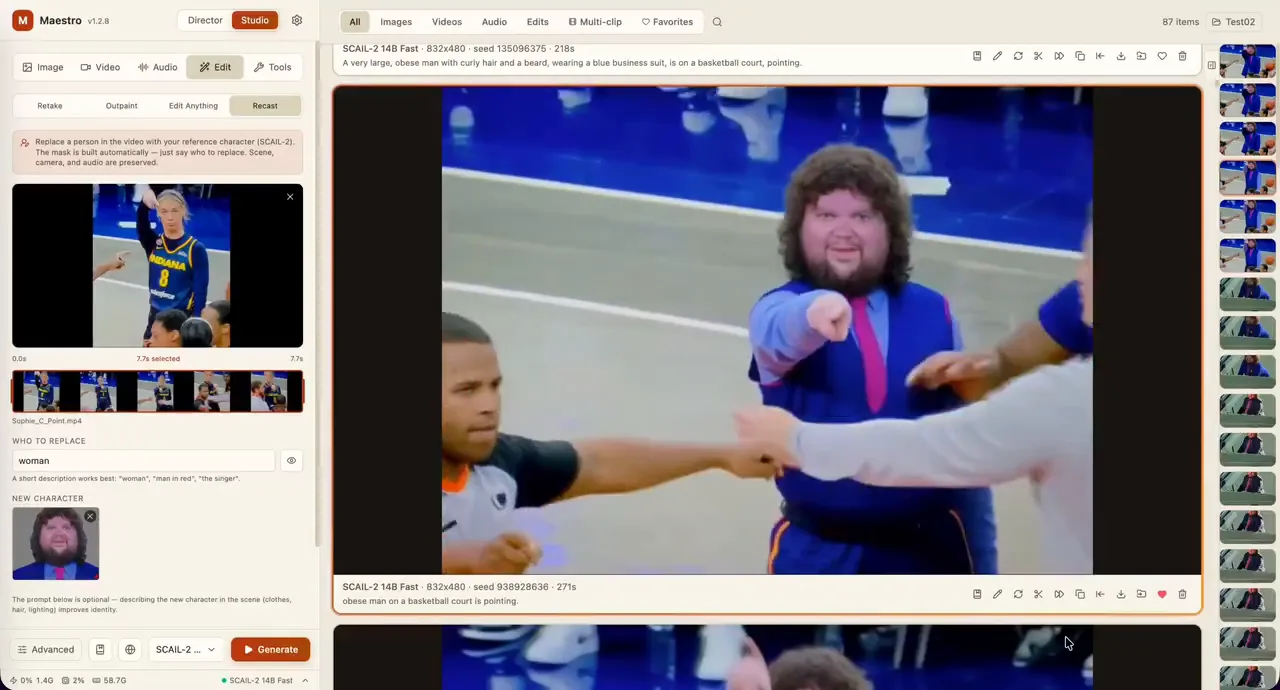
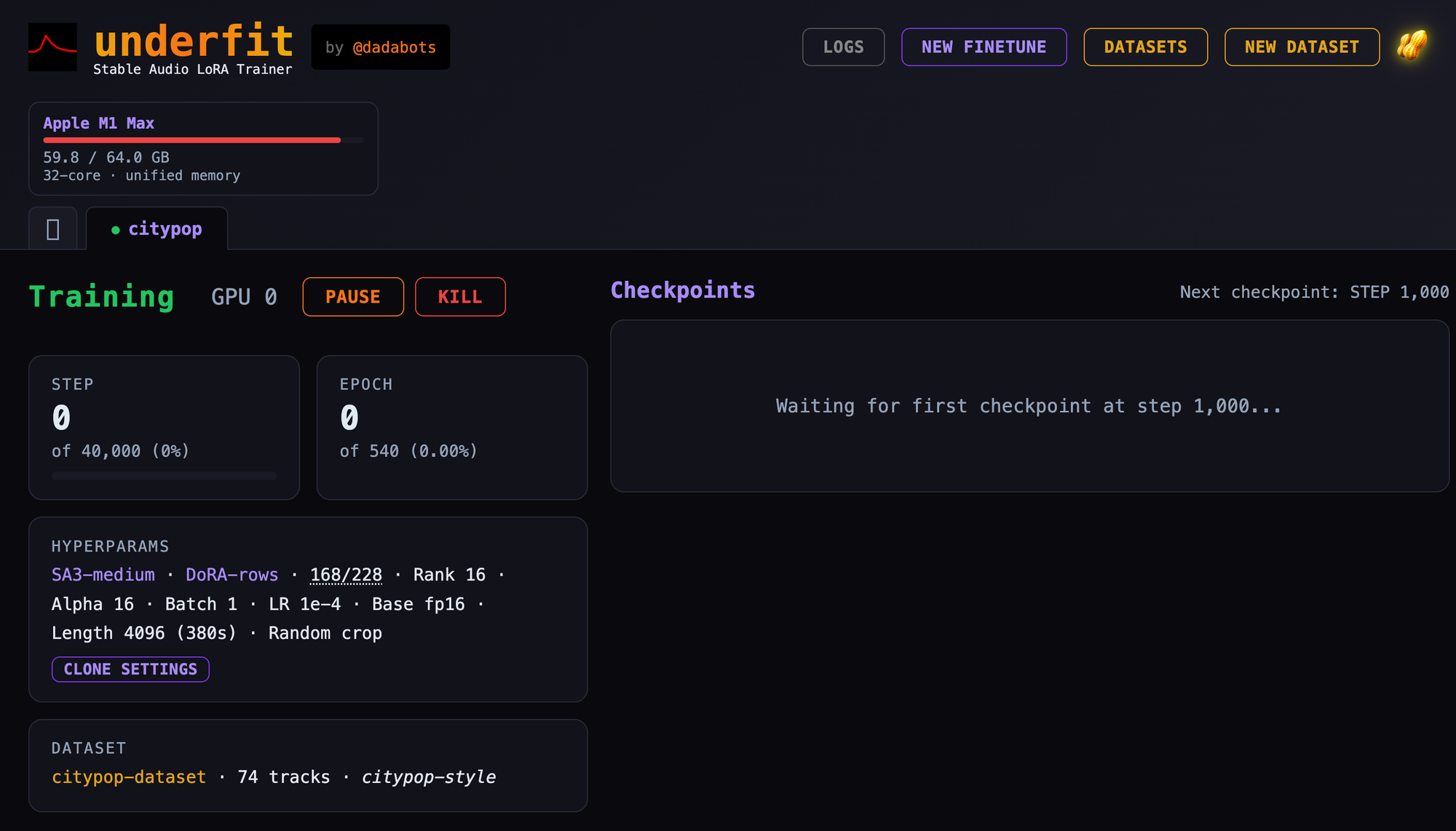
Type a description into the box and click “Run” to have the app create several pictures that match your prompt. The generated images appear in a gallery below, and you can download a screenshot of ...
⚡️ Efficient 6B parameter image generation model with sub-second inference. Generate high-quality, photorealistic images with only 8 inference steps. Features bilingual text rendering (Chinese & English) and Single-Stream Diffusion Transformer architecture.
PierrunoYT/TranslateGemma-Pinokiov5.0updated 15d ago
🌍 TranslateGemma - Google's open-source multilingual translation AI. Translate text across 55+ languages and extract/translate text from images. Powered by Gemma 3 architecture.