Alexandria — Turn Any Book Into a Multi-Voice Audiobook With AI (Local, Free, Open Source)

Alexandria Audiobook Generator
Alexandria is an open-source tool that turns any book or novel into a fully-voiced, multi-character audiobook using AI, all running locally on your machine. It works through a two-stage pipeline: first, an LLM (like Qwen, via LM Studio or Ollama) reads your text and automatically annotates it into a structured script, identifying characters, dialogue, narration, and even style directions (e.g., "fearful surprise" or "slow and threatening"). Then, Qwen3 TTS generates the actual speech, with different voices for each character.
 |
 |
 |
 |
|---|
##Sample: https://vocaroo.com/1cG82gVS61hn
How It Works
Upload a .txt or .md file of your book → the LLM breaks it into a JSON script with speaker labels, dialogue, and emotion/style cues → you assign voices to each character → the TTS engine renders the audio → you review and edit in the browser → you get a finished MP3 audiobook.
Major Features
LLM-powered script annotation automatically identifies speakers, splits narration from dialogue, and writes natural style directions for each line. Works with any OpenAI-compatible API (local or cloud).
Voice cloning clone any voice from just a 5–15 second audio sample, or choose from 9 built-in voices with full style/emotion control.
LoRA voice pipeline supports Qwen3 TTS LoRA fine-tuned voices for higher-quality, more consistent character voices beyond basic cloning.
Browser-based editor with per-line editing web UI lets you review and edit every single line's speaker, text, and style. You can selectively regenerate individual chunks one at a time without redoing the whole book, making it easy to fix a single mispronunciation or tweak delivery.
Natural non-verbal sounds the LLM generates real pronounceable vocalizations (gasps, laughter, sighs) with context-aware delivery directions, not robotic tags.
Flexible export including Audacity integration get a single combined MP3, individual voiceline files per line, or a one-click Audacity export that generates per-speaker WAV tracks, a
.lofproject file, and chunk labels. Just unzip, open in Audacity, and you get a full multi-track project with each character on their own track for fine-tuning timing, effects, and mixing.Batch rendering includes an experimental fast mode (~5x speedup) for bulk audio generation.
REST API full programmatic access for scripting and automation.
Quick Start
The interface is split into a 5-step core pipeline (green tabs, numbered) and advanced tools (blue tabs, unnumbered). You only need the core pipeline to produce an audiobook.
Core Pipeline
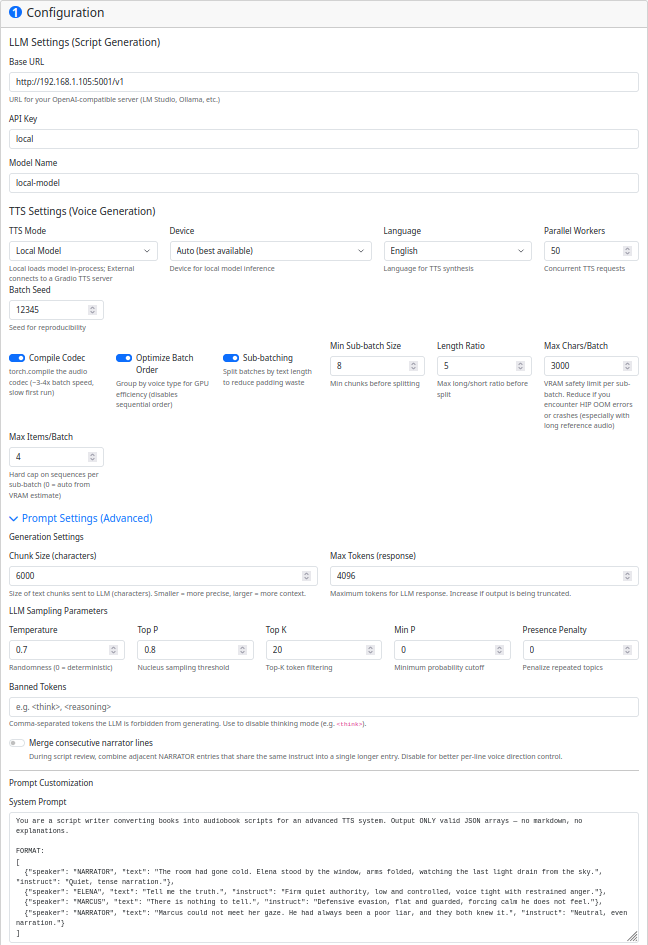
Step 1 — Setup
Configure your LLM connection and TTS engine. At minimum you need:
- LLM Base URL:
http://localhost:1234/v1(LM Studio) orhttp://localhost:11434/v1(Ollama) - LLM API Key: Your API key (use
localfor local servers) - LLM Model Name: The model to use (e.g.,
qwen2.5-14b) - TTS Mode:
local(built-in, recommended) — loads models directly, no external server needed - Click Save Configuration when done
Step 2 — Script
- Select your book file (.txt or .md) using the file picker — it uploads automatically
- Click Generate Annotated Script — this sends the book to your LLM to split it into annotated chunks with speaker labels and voice directions
- (Optional) Click Review Script if the generated script has issues — this runs a second LLM pass to fix speaker misattributions or formatting problems
- You can save the script for later use with the Save feature below
Step 3 — Voices
Each character detected in the script gets a voice card. For each speaker:
- Choose a voice type: Custom Voice (easiest), Clone Voice, LoRA Voice, or Voice Design
- For Custom Voice, pick from 9 presets (Ryan, Serena, Aiden, etc.) and optionally set a character style (e.g., "Heavy Scottish accent")
- Changes save automatically — see Voice Types for guidance on each type
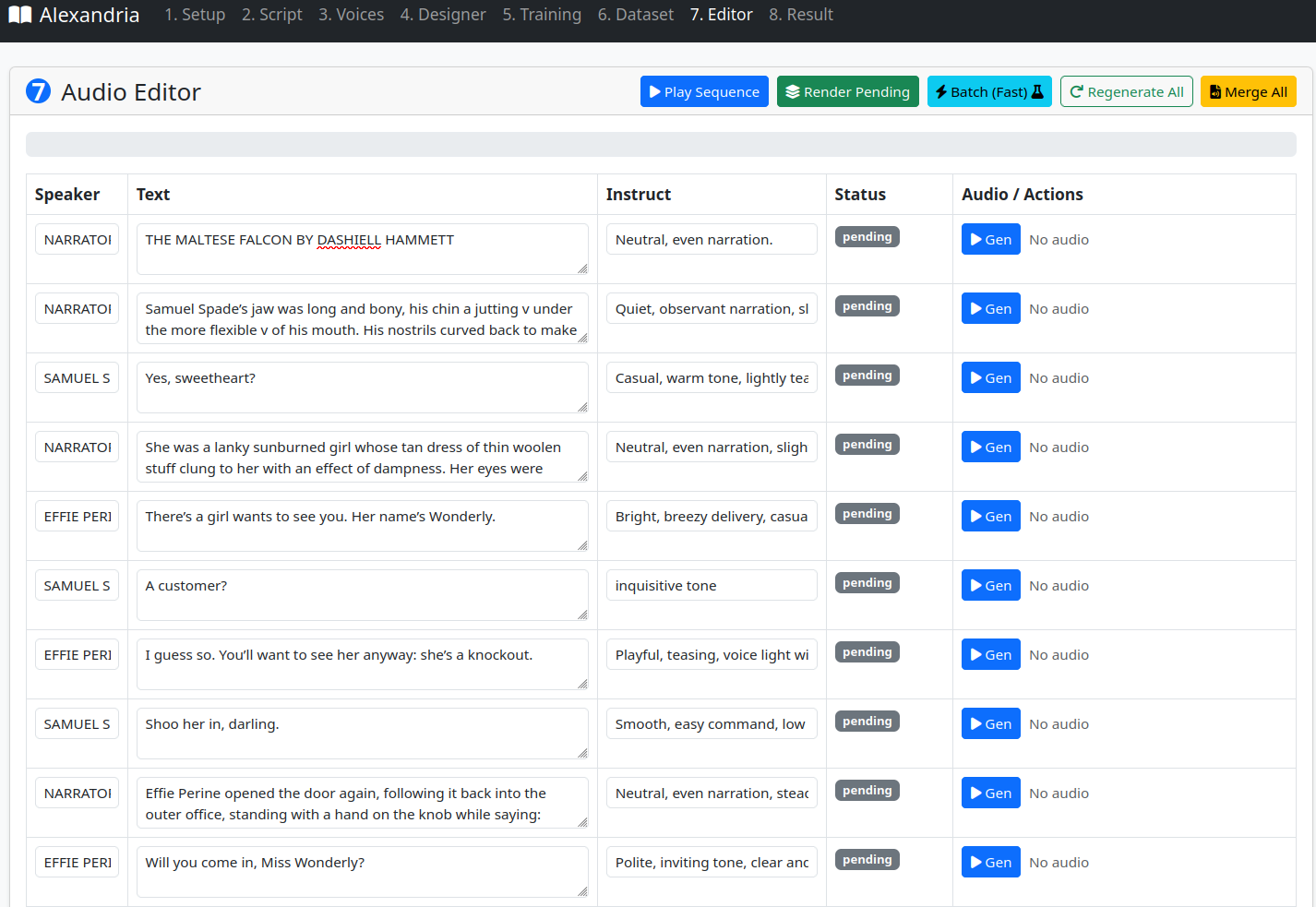
Step 4 — Editor
- Click Render Pending to generate audio for all chunks in batch
- Listen to individual chunks or click Play Sequence to preview in order
- Edit any chunk's text, speaker, or instruct inline and regenerate it individually
- When satisfied, click Merge All to combine everything into the final audiobook
Step 5 — Result
- Listen to the finished audiobook in the browser
- Download as MP3, or click Export to Audacity for per-speaker WAV tracks
Advanced Tools (Optional)
These tabs are for power users who want more control over voice creation:
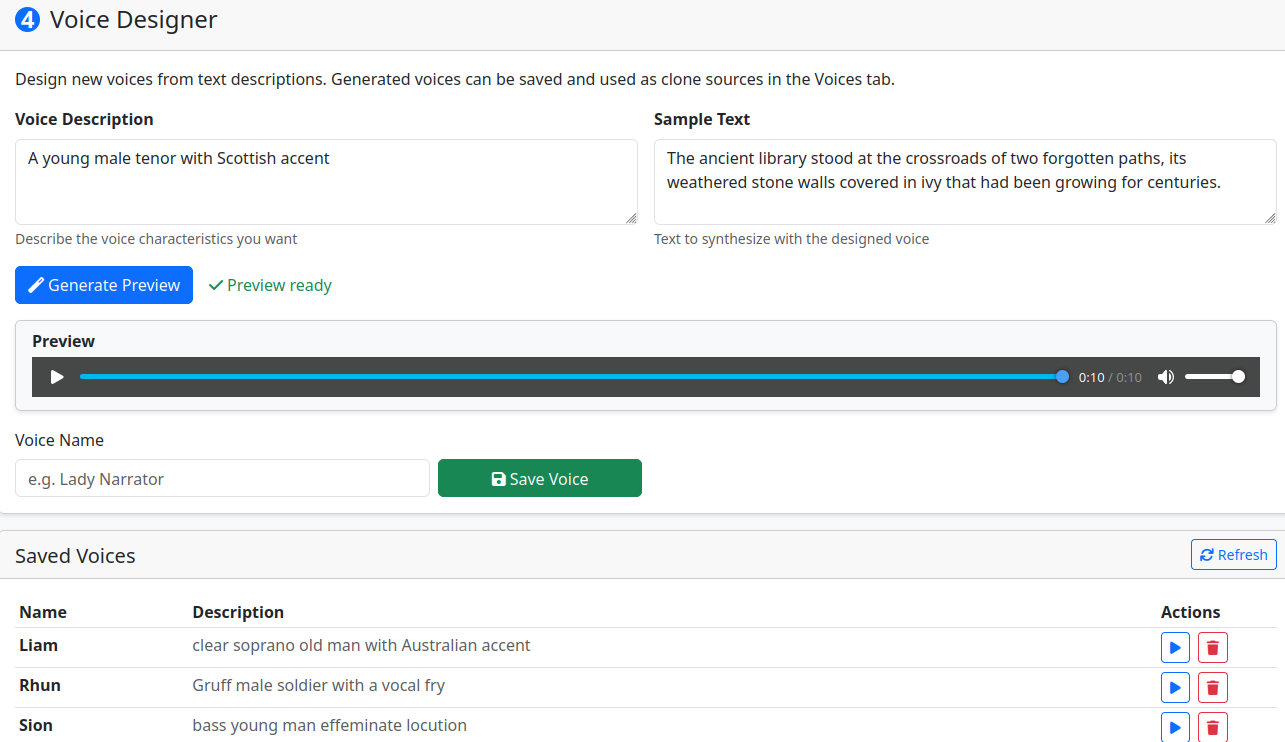
Designer — Create new voices from text descriptions (e.g., "A warm elderly woman with a gentle raspy voice"). Save them to use as clone references in the Voices tab
Dataset — Build LoRA training datasets interactively, one sample at a time with audio preview
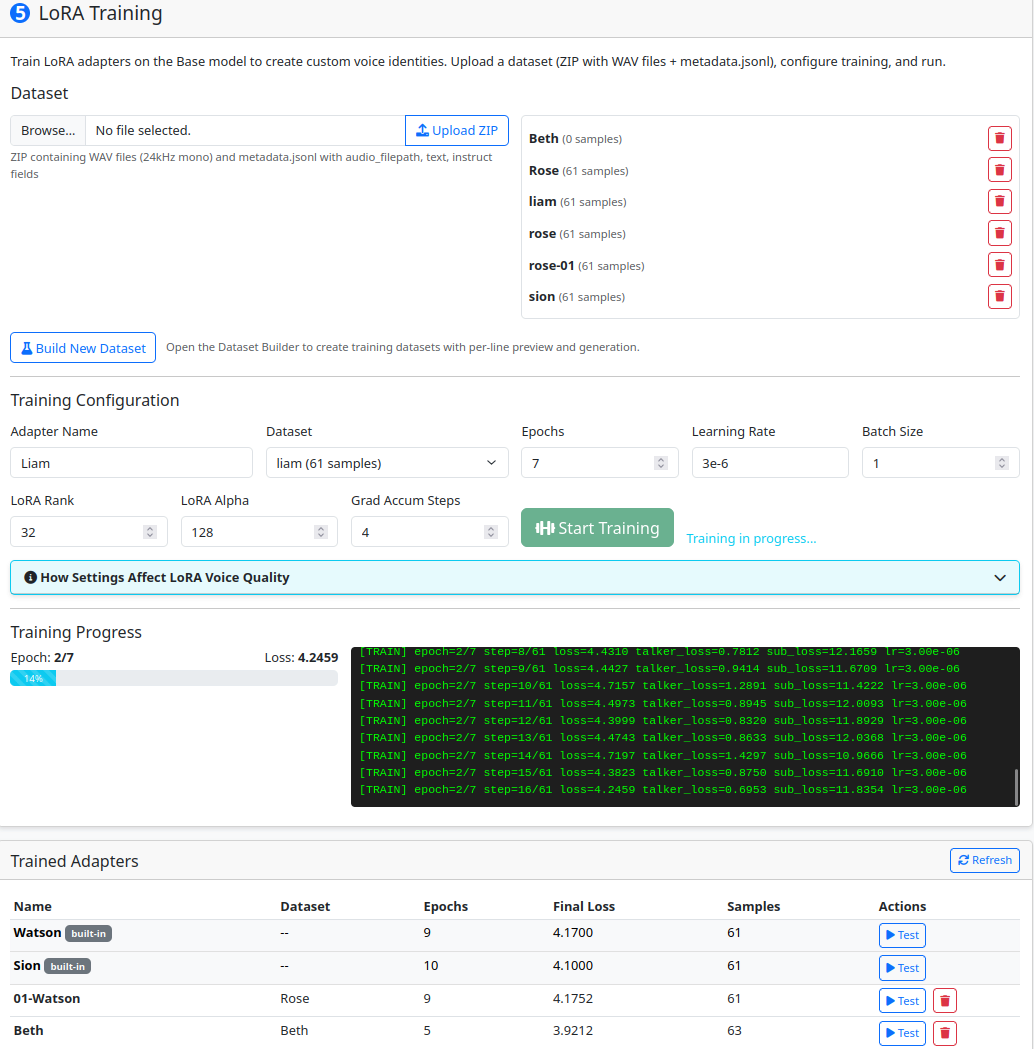
Training — Train LoRA adapters on voice datasets to create persistent voice identities that follow instruct directions
REQUIREMENTS
- GPU: 8 GB VRAM minimum, 16 GB+ recommended. NVIDIA (CUDA 11.8+) or AMD (ROCm 6.0+).
- RAM: 16 GB recommended (8 GB minimum).
- Disk: ~20 GB minimum. Breakdown: ~8 GB venv/PyTorch, ~7 GB for 2 model variants (CustomVoice + Base), ~3-5 GB working space for generated audio.
- CPU: Not a bottleneck, any modern multi-core.
- Note: Only one model occupies VRAM at a time during generation. Batch throughput scales with free VRAM after model loading. Clone/LoRA voices need more VRAM per sequence than custom voices due to reference audio encoding.
Please provide feedback on what improvements or features you would like for your particular usecase.
For instructions and references visit the Wiki: https://github.com/Finrandojin/alexandria-audiobook/wiki