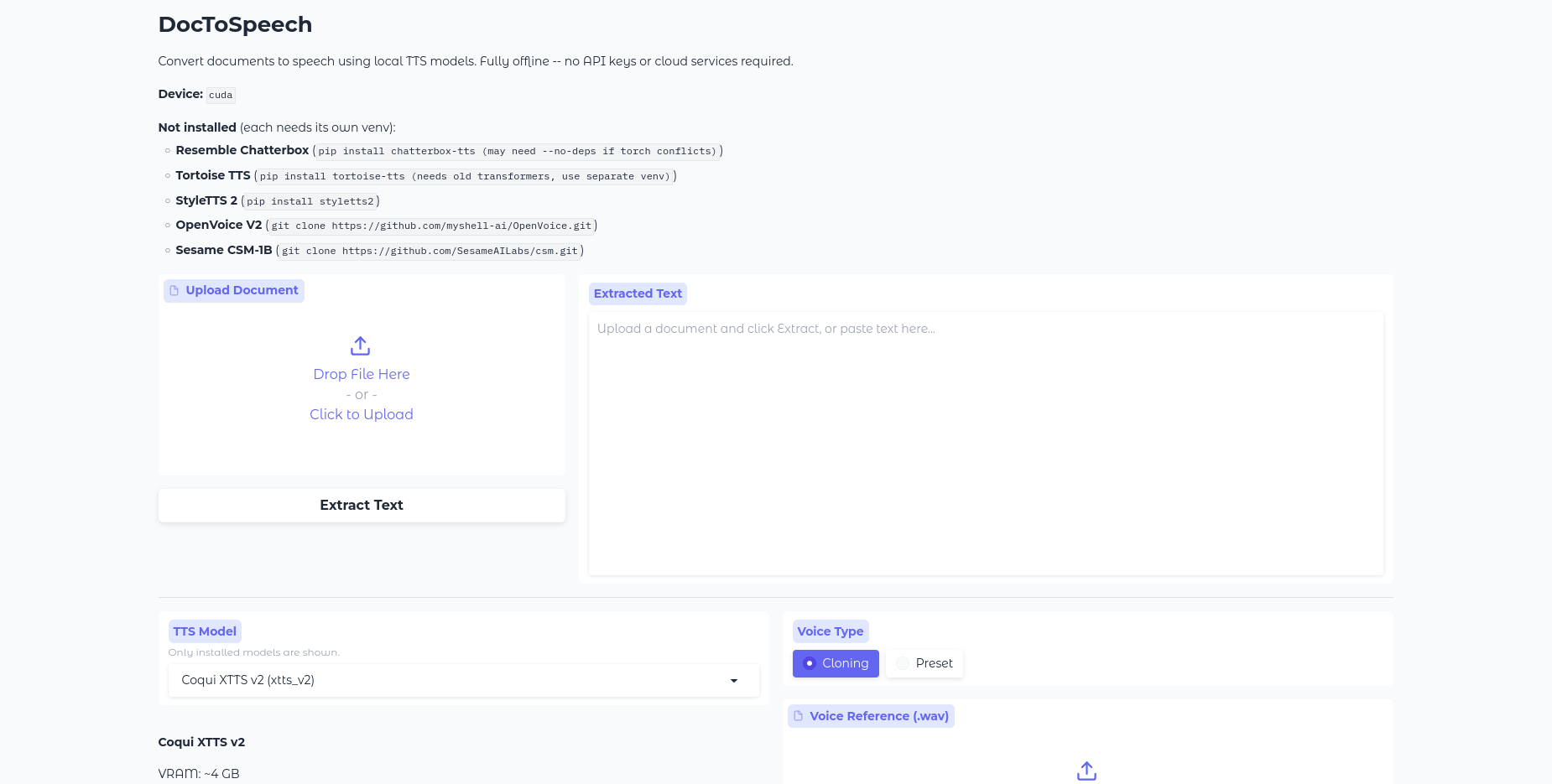
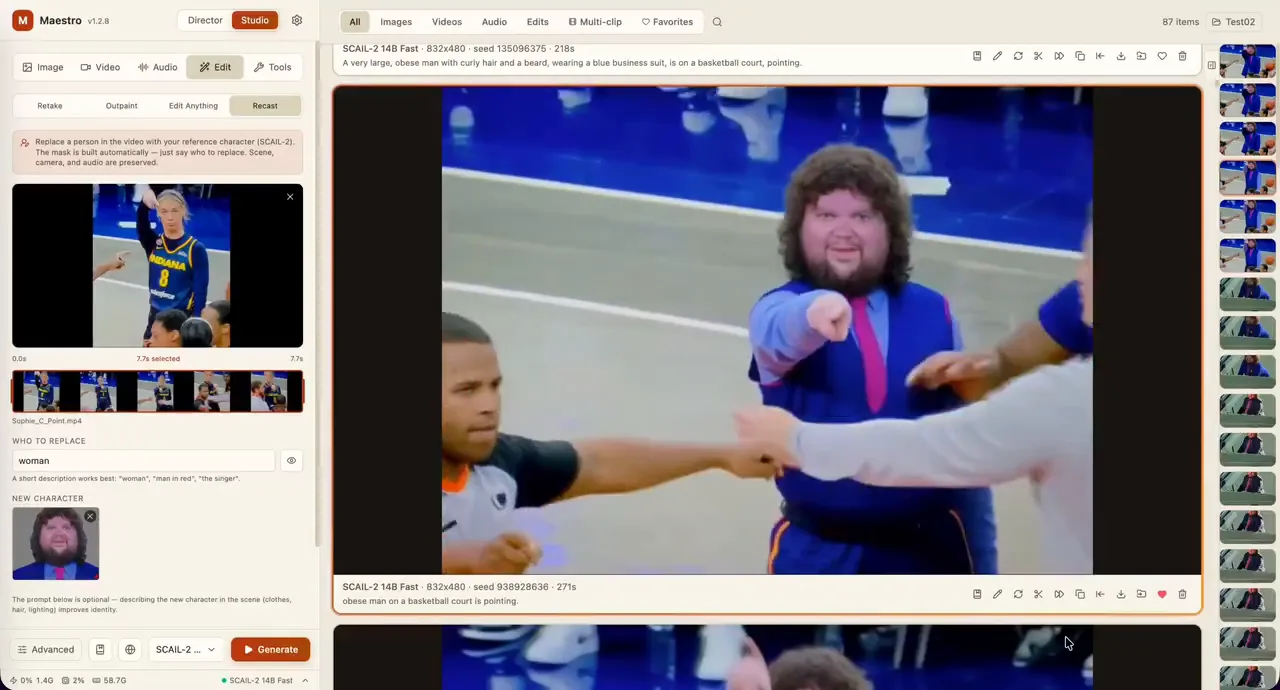
Artist is a training-free text-driven image stylization method. You give an image and input a prompt describing the desired style, Artist give you the stylized image in that style. The detail of the original image and the style you provide is harmonically integrated https://huggingface.co/spaces/fffiloni/Artist
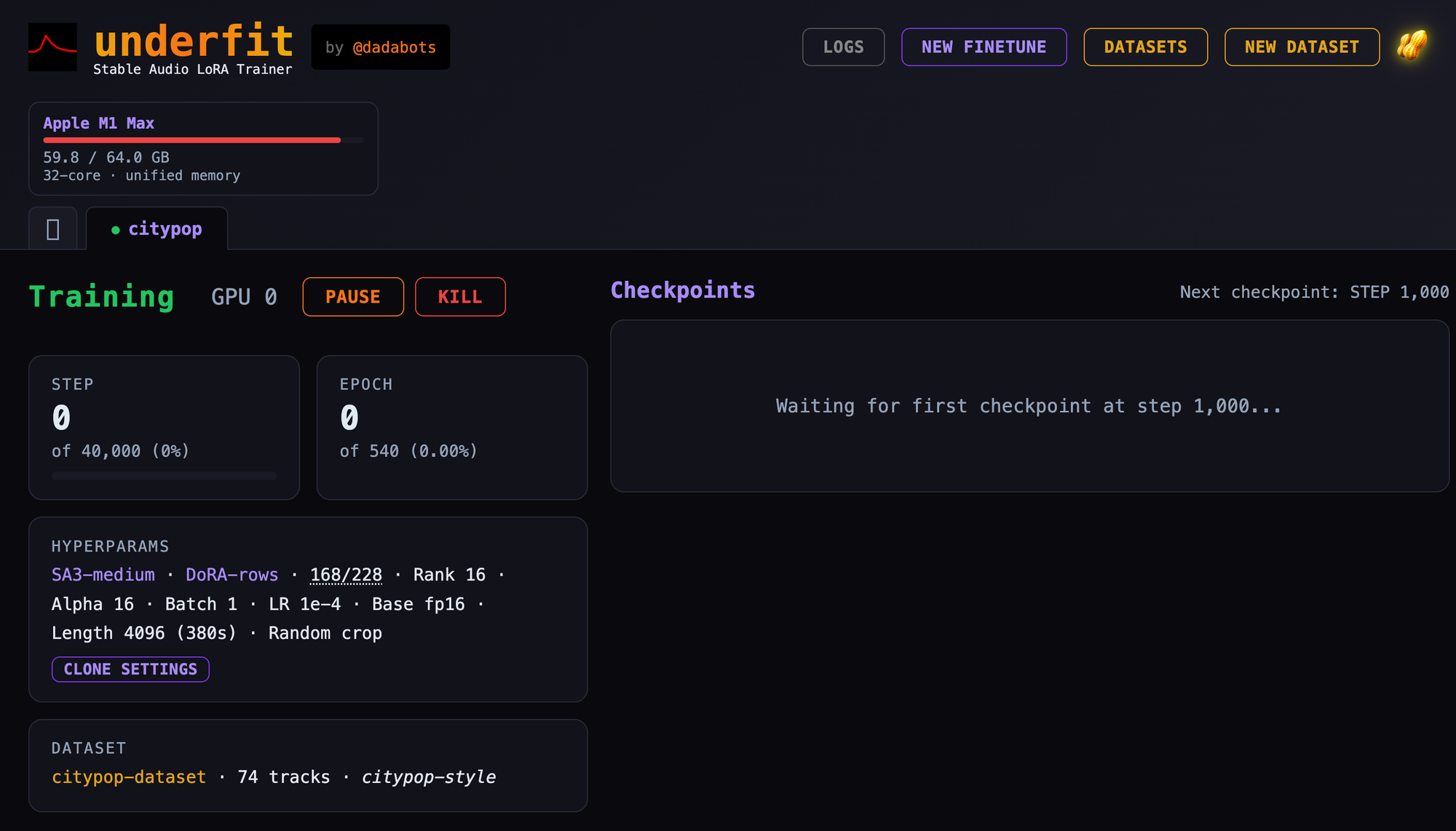
Nari Dia is a powerful text-to-speech (TTS) application based on the Dia-1.6B model from Nari Labs. This application allows you to convert text into natural-sounding speech with various customization options.