
Over the past several updates, I’ve been working through community reports and taking a closer look at how TT...
Launcher updates
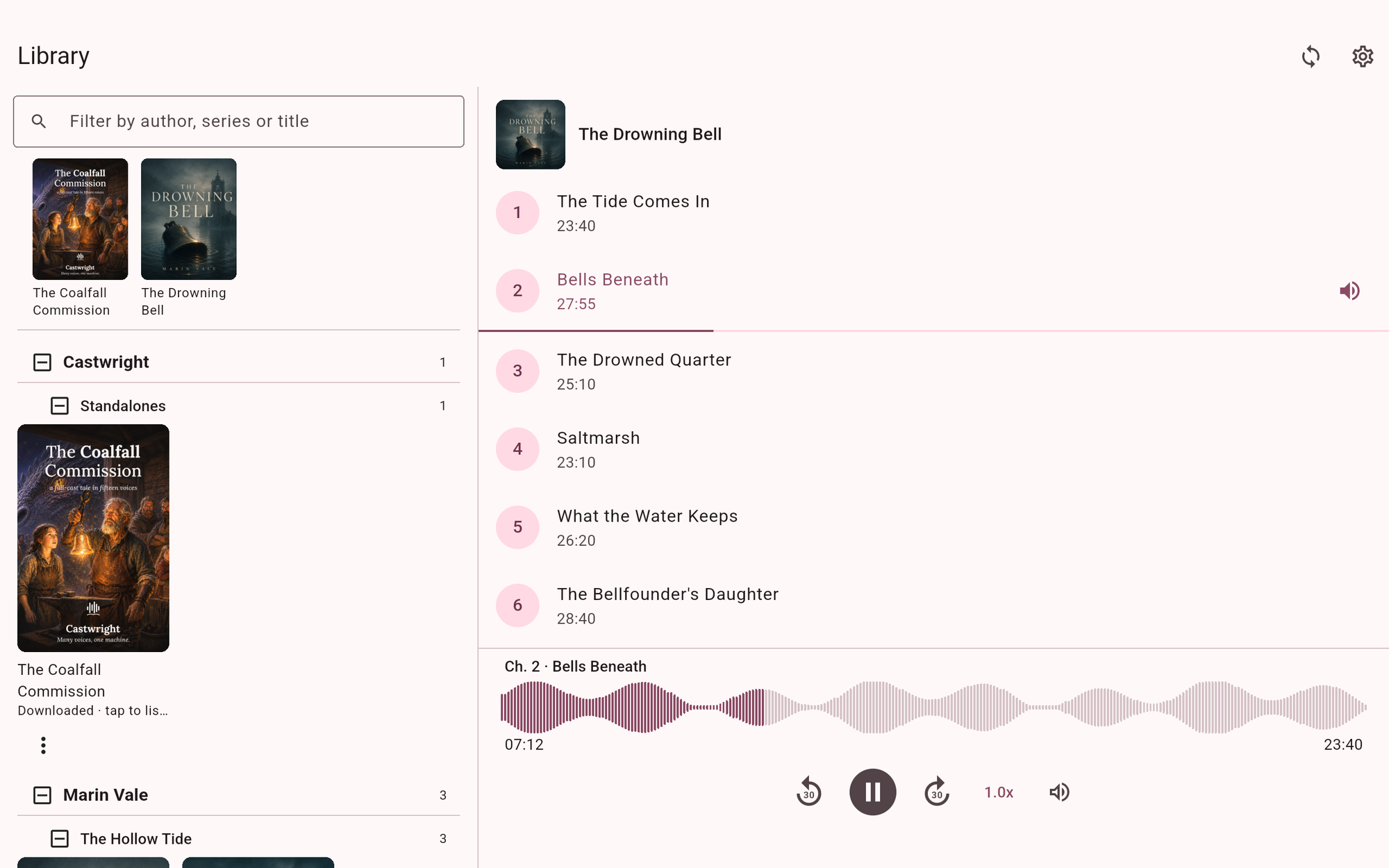
Castwright v1.14.0 — Chinese and Japanese join the cast, and the app grows up on tablets
Quick recap for anyone new: Castwright turns a book into a full-cast audiobook — every character in its own v...
ComfyUI Installer v1.2 — Multiple Instances, GPU Selection and Improved Restarts

🚀 ComfyUI Installer v1.2 — Multiple Instances, GPU Selection and Improved Restarts The Inteliweb AI ComfyUI ...

Remix mode: drop your trained face into ANY scene - 100% on your Mac

Phosphene's new Remix mode fuses two things into a single local render: 1) a Character you trained - a LoRA o...
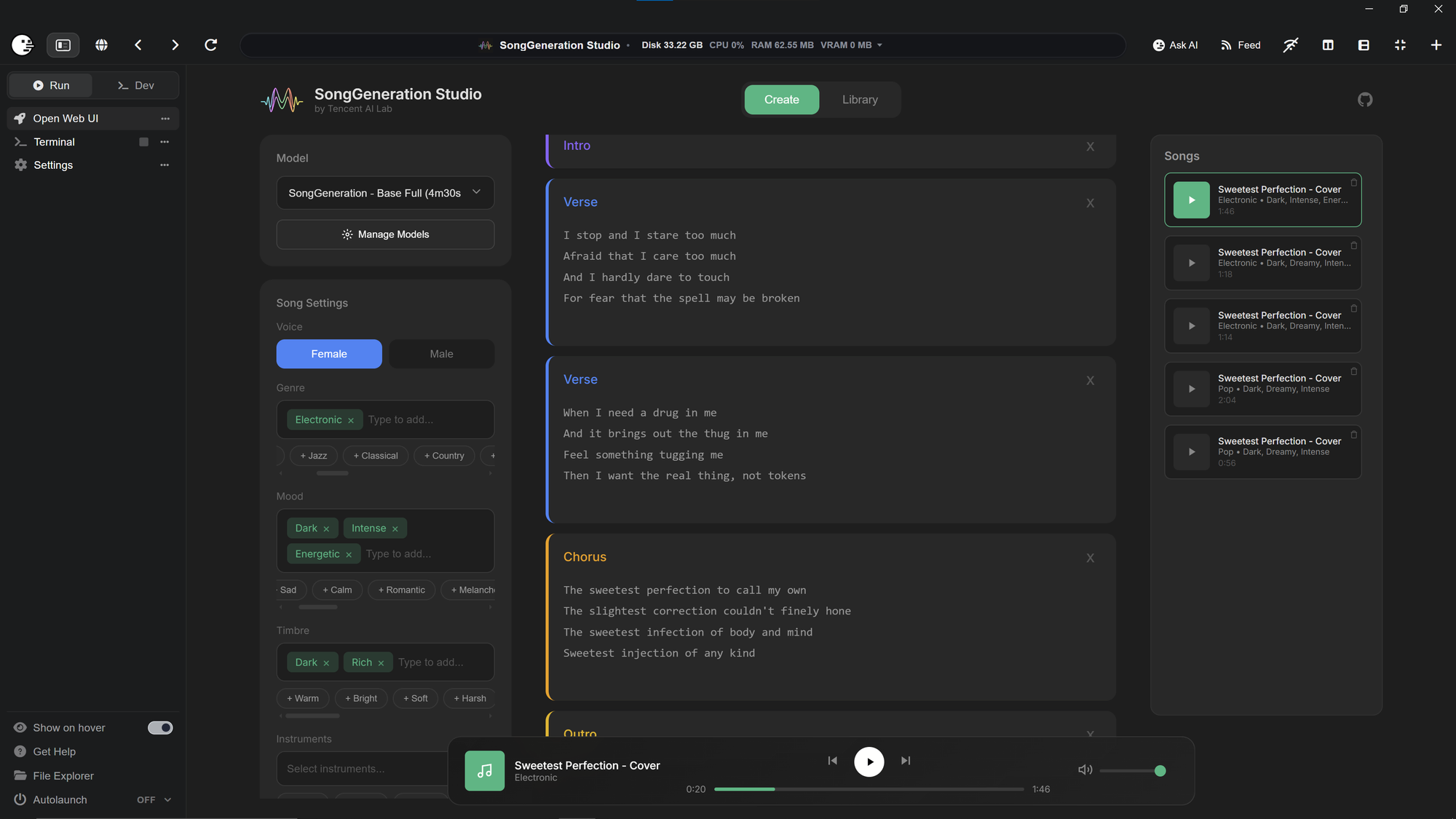
Songgeneration - Fixed

You may have noticed that all Pinokio installer of SongGeneration-Studio and SongGeneration stopped working. ...
Store
SOME: Singing-Oriented MIDI Extractor.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
An open-source, code-first Python toolkit for building, evaluating, and deploying sophisticated AI agents with flexibility and control.

A lightweight utility that makes the Windows taskbar translucent/transparent.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
High-Resolution 3D Assets Generation with Large Scale Hunyuan3D Diffusion Models.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
CLI proxy that reduces LLM token consumption by 60-90% on common dev commands. Single Rust binary, zero dependencies
📦 The official Nextcloud installation method. Provides easy deployment and maintenance with most features included in this one Nextcloud instance.
Contribute to tuvshinorg/AI-YouTube-Video-Generator development by creating an account on GitHub.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Enter the text you want to hear, then pick a built‑in speaker, upload a short recording to clone its voice, or describe a voice style you imagine. The app quickly creates an audio file you can list...
Edit any pose with Qwen Edit 2511 Any Pose LoRA
Your AI second brain. Self-hostable. Get answers from the web or your docs. Build custom agents, schedule automations, do deep research. Turn any online or local LLM into your personal, autonomous AI (gpt, claude, gemini, llama, qwen, mistral). Get started - free.
Ultra-Realistic Image 2 Video [ UNCENSORED ]
Create a 1M faces 3D colored model from an image!
Contribute to WaveSpeedAI/wavespeed-comfyui development by creating an account on GitHub.
🎬 Transform long-form YouTube videos (podcasts, interviews, vlogs) into engaging short-form content for TikTok, Instagram Reels, and YouTube Shorts — all with a single command.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.